
Lecture 17: Introduction to natural language processing#
UBC 2023-24
Instructor: Varada Kolhatkar and Andrew Roth
Imports#
import os
import re
import string
import sys
import time
sys.path.append(os.path.join(os.path.abspath("."), "code"))
from plotting_functions_unsup import *
import IPython
import numpy as np
import numpy.random as npr
import pandas as pd
from comat import CooccurrenceMatrix
from nltk.corpus import stopwords
from nltk.tokenize import sent_tokenize, word_tokenize
from preprocessing import MyPreprocessor
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
import nltk
nltk.download('stopwords')
[nltk_data] Downloading package stopwords to
[nltk_data] /Users/kvarada/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
True
Learning objectives#
Broadly explain what is natural language processing (NLP).
Name some common NLP applications.
Explain the general idea of a vector space model.
Explain the difference between different word representations: term-term co-occurrence matrix representation and Word2Vec representation.
Describe the reasons and benefits of using pre-trained embeddings.
Load and use pre-trained word embeddings to find word similarities and analogies.
Demonstrate biases in embeddings and learn to watch out for such biases in pre-trained embeddings.
Use word embeddings in text classification and document clustering using
spaCy.Explain the general idea of topic modeling.
Describe the input and output of topic modeling.
Carry out basic text preprocessing using
spaCy.
What is Natural Language Processing (NLP)?#
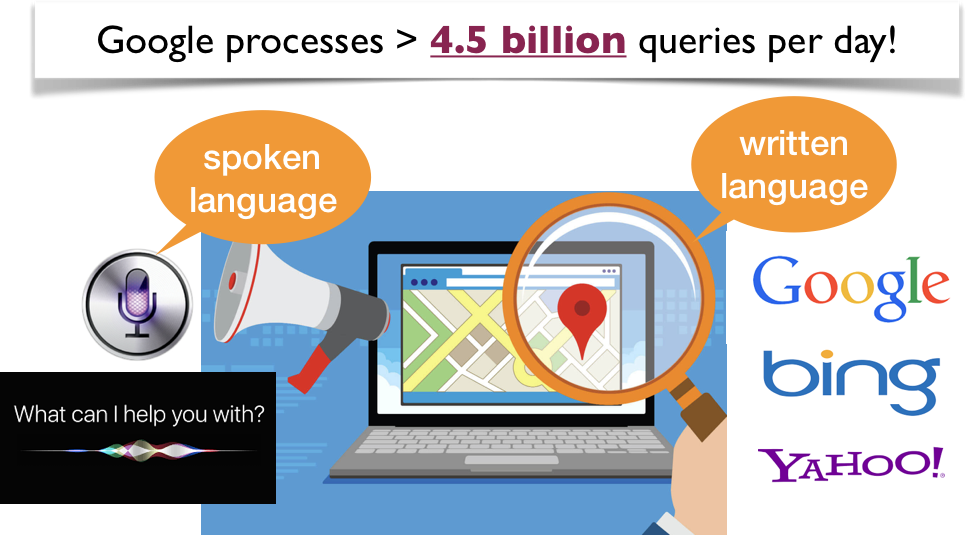
What should a search engine return when asked the following question?

What is Natural Language Processing (NLP)?#
How often do you search everyday?#
What is Natural Language Processing (NLP)?#
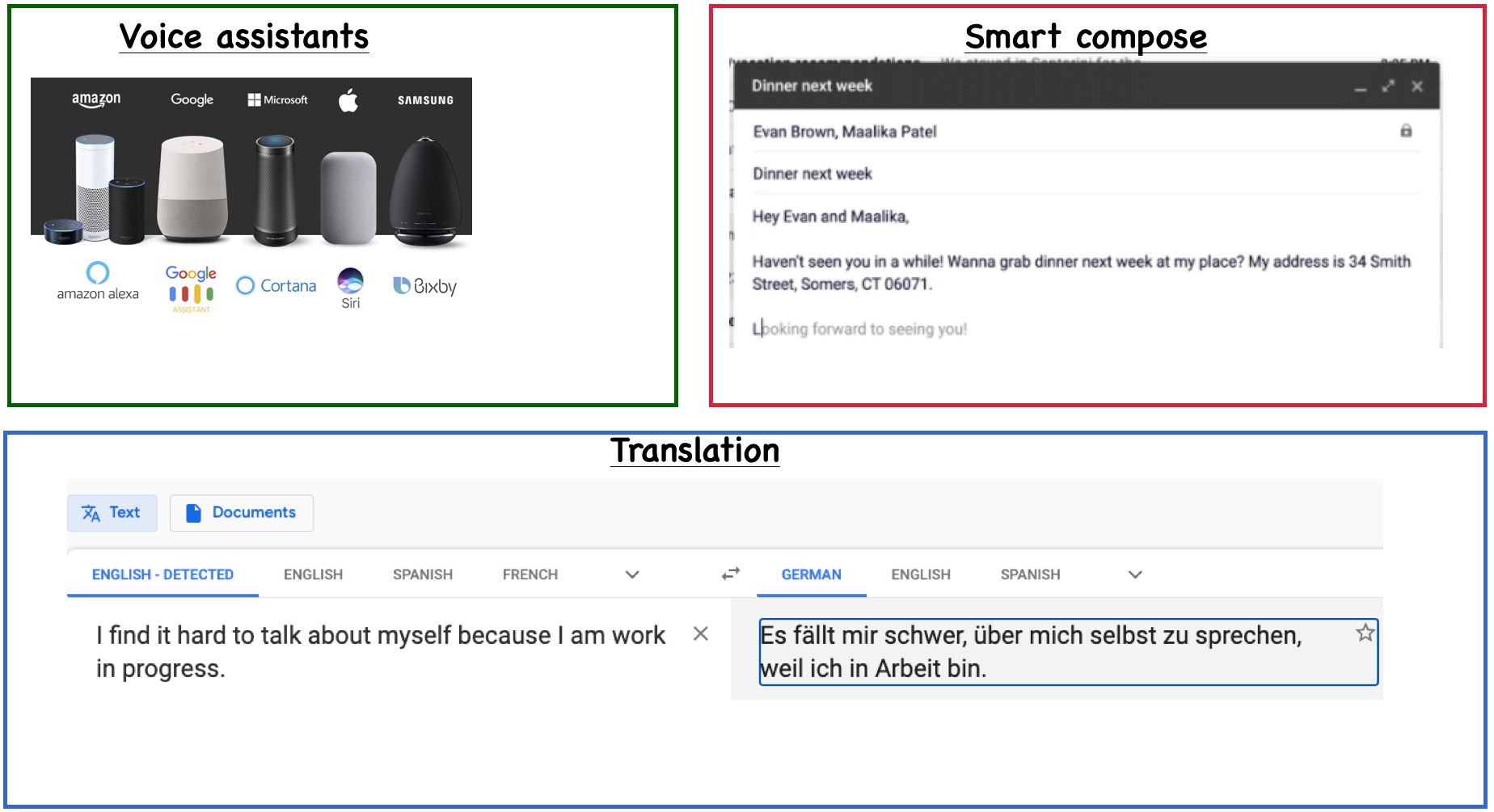
Everyday NLP applications#
NLP in news#
Often you’ll see NLP in news. Some examples:
Why is NLP hard?#
Language is complex and subtle.
Language is ambiguous at different levels.
Language understanding involves common-sense knowledge and real-world reasoning.
All the problems related to representation and reasoning in artificial intelligence arise in this domain.
Example: Lexical ambiguity#
Example: Referential ambiguity#

Ambiguous news headlines#
PROSTITUTES APPEAL TO POPE
appeal to means make a serious or urgent request or be attractive or interesting?
KICKING BABY CONSIDERED TO BE HEALTHY
kicking is used as an adjective or a verb?
MILK DRINKERS ARE TURNING TO POWDER
turning means becoming or take up?
Overall goal#
Give you a quick introduction to you of this important field in artificial intelligence which extensively used machine learning.

Today’s plan
Word embeddings
Topic modeling
Basic text preprocessing
Word embeddings#
# It'll take a while to run this when you try it out for the first time.
import gensim.downloader as api
google_news_vectors = api.load("word2vec-google-news-300")
def analogy(word1, word2, word3, model=google_news_vectors):
"""
Returns analogy word using the given model.
Parameters
--------------
word1 : (str)
word1 in the analogy relation
word2 : (str)
word2 in the analogy relation
word3 : (str)
word3 in the analogy relation
model :
word embedding model
Returns
---------------
pd.dataframe
"""
print("%s : %s :: %s : ?" % (word1, word2, word3))
sim_words = model.most_similar(positive=[word3, word2], negative=[word1])
return pd.DataFrame(sim_words, columns=["Analogy word", "Score"])
analogy("Italy", "pizza", "Japan")
Italy : pizza :: Japan : ?
| Analogy word | Score | |
|---|---|---|
| 0 | sushi | 0.542754 |
| 1 | ramen | 0.541916 |
| 2 | bento | 0.539965 |
| 3 | teriyaki | 0.502705 |
| 4 | yakisoba | 0.502351 |
| 5 | takoyaki | 0.501550 |
| 6 | onigiri | 0.501540 |
| 7 | burger | 0.495270 |
| 8 | ramen_noodle | 0.493126 |
| 9 | noodle | 0.490753 |
Word embeddings#
The idea is to create representations of words so that distances between words in the feature space indicate relationships between them.

(Attribution: Jurafsky and Martin 3rd edition)
Why do we care about word representations?#
So far we have been talking about sentence or document representations.
Now we are going one step back and talking about word representations.
Word is a basic unit of text and in order to capture meaning of text it is useful to capture word meaning (e.g., in terms of relationships between words).
Word meaning#
A favourite topic of philosophers for centuries.
An example from legal domain: Are hockey gloves “gloves, mittens, mitts” or “articles of plastics”?
Canada (A.G.) v. Igloo Vikski Inc. was a tariff code case that made its way to the SCC (Supreme Court of Canada). The case disputed the definition of hockey gloves as either "gloves, mittens, or mitts" or as "other articles of plastic."

Word meaning: ML and Natural Language Processing (NLP) view#
Modeling word meaning that allows us to
draw useful inferences to solve meaning-related problems
find relationship between words, e.g., which words are similar, which ones have positive or negative connotations
Word similarity#
Suppose you are carrying out sentiment analysis.
Consider the sentences below.
S1: The movie was awesome!!
S2: The movie was amazing!!
Here we would like to capture similarity between awesome and amazing in reference to sentiment analysis task.
Overview of dot product and cosine similarity#
To create a vector space where similar words are close together, we need some metric to measure distances between representations.
We have used the Euclidean distance before for numeric features.
For sparse features, the most commonly used metrics are Dot product and Cosine distance.
Let’s look at an example.
vec1 = np.array([2.0, 4.0, 3.0])
vec2 = np.array([5.0, 1.0, 0.0])
Euclidean distance
# Euclidean Distance
euclidean_distance = np.linalg.norm(vec1 - vec2)
print(f"Euclidean Distance: {euclidean_distance:.4f}")
Euclidean Distance: 5.1962
dot product similarity: $\(similarity_{dot product}(vec1,vec2) = vec1.vec2\)$
# Dot Product
dot_product = np.dot(vec1, vec2)
print(f"Dot Product: {dot_product:.4f}")
Dot Product: 14.0000
Cosine similarity: normalized version of dot product. $\(similarity_{cosine}(vec1,vec2) = \frac{vec1.vec2}{\left\lVert vec1\right\rVert_2 \left\lVert vec2\right\rVert_2}\)$
Where,
The L2 norm of \(vec1\) is the magnitude of \(vec1\) $\(\left\lVert vec1\right\rVert_2 = \sqrt{\sum_i vec1_i^2}\)$
The L2 norm of \(vec2\) is the magnitude of \(vec2\) $\(\left\lVert vec2\right\rVert_2 = \sqrt{\sum_i vec2_i^2}\)$
# Cosine Similarity
cosine_similarity = np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
print(f"Cosine Similarity: {cosine_similarity:.4f}")
Cosine Similarity: 0.5098
Discussion question#
Suppose you are recommending items based on similarity between items. Given a query vector “Query” in the picture below and the three item vectors, determine the ranking for the three similarity measures below:
Similarity based on Euclidean distance
similarity based on dot product
Cosine similarity
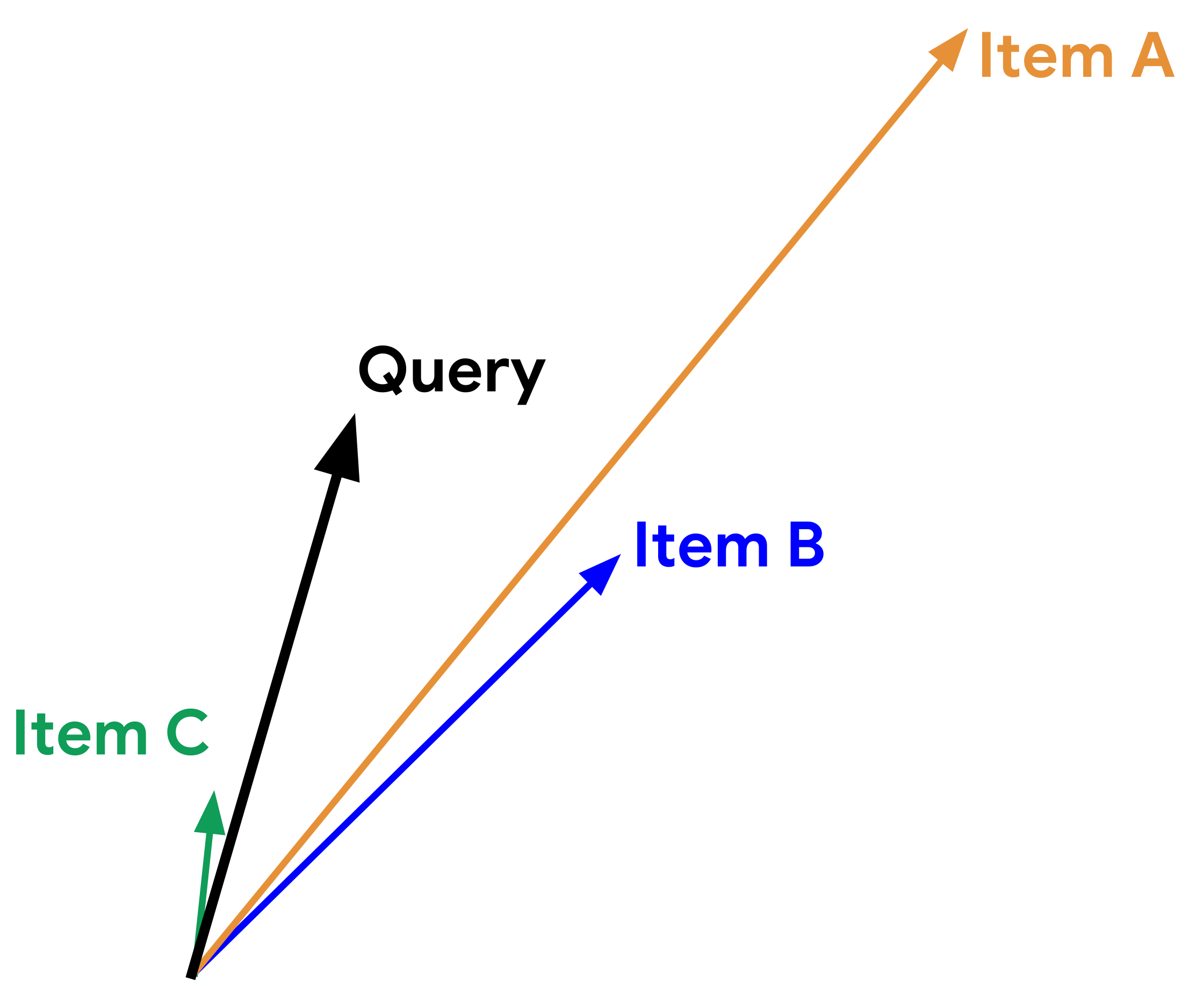
Adapted from here.
Word representations#
Activity 1: Brainstorm ways to represent words (~2 mins)#
Suppose you are building a question answering system and you are given the following question and three candidate answers.
What kind of relationship between words would we like our representation to capture in order to arrive at the correct answer?
Question: How tall is Machu Picchu?
Candidate 1: Machu Picchu is 13.164 degrees south of the equator.
Candidate 2: The official height of Machu Picchu is 2,430 m.
Candidate 3: Machu Picchu is 80 kilometres (50 miles) northwest of Cusco.
Let’s explore different ways to represent words.
First, let’s look at two simplistic word representations
One-hot representation
Term-term co-occurrence matrix
Simplest representation: One-hot representation of words#
Example: Consider the sentence
How tall is Machu_Picchu ?
What is the one-hot representation for the word tall?
Vocabulary size = 5 and index of the word tall = 1
One-hot vector for tall: \(\begin{bmatrix} 0 & 1 & 0 & 0 & 0 \end{bmatrix}\)
Build vocabulary containing all unique words in the corpus.
One-hot representation of a word is a vector of length \(V\) such that the value at word index is 1 and all other indices is 0.
def get_onehot_encoding(word, vocab):
onehot = np.zeros(len(vocab), dtype="float64")
onehot[vocab[word]] = 1
return onehot
from sklearn.metrics.pairwise import cosine_similarity
def print_cosine_similarity(df, word1, word2):
"""
Returns similarity score between word1 and word2
Arguments
---------
df -- (pandas.DataFrame)
Dataframe containing word representations
word1 -- (array)
Representation of word1
word2 -- (array)
Representation of word2
Returns
--------
None. Returns similarity score between word1 and word2 with the given representation
"""
vec1 = df.loc[word1].to_numpy().reshape(1, -1)
vec2 = df.loc[word2].to_numpy().reshape(1, -1)
sim = cosine_similarity(vec1, vec2)
print(
"The dot product between %s and %s: %0.2f and cosine similarity is: %0.2f"
% (word1, word2, np.dot(vec1.flatten(), vec2.flatten()), sim)
)
Vocabulary and one-hot encoding#
corpus = (
"""how tall is machu_picchu ? the official height of machu_picchu is 2,430 m ."""
)
unique_words = list(set(corpus.split()))
unique_words.sort()
vocab = {word: index for index, word in enumerate(unique_words)}
print("Size of the vocabulary: %d" % (len(vocab)))
print(vocab)
Size of the vocabulary: 12
{'.': 0, '2,430': 1, '?': 2, 'height': 3, 'how': 4, 'is': 5, 'm': 6, 'machu_picchu': 7, 'of': 8, 'official': 9, 'tall': 10, 'the': 11}
data = {}
for word in vocab:
data[word] = get_onehot_encoding(word, vocab)
ohe_df = pd.DataFrame(data).T
ohe_df
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| . | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2,430 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ? | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| height | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| how | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| is | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| m | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| machu_picchu | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| of | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| official | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| tall | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| the | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
print_cosine_similarity(ohe_df, "tall", "height")
print_cosine_similarity(ohe_df, "tall", "official")
The dot product between tall and height: 0.00 and cosine similarity is: 0.00
The dot product between tall and official: 0.00 and cosine similarity is: 0.00
/var/folders/b3/g26r0dcx4b35vf3nk31216hc0000gr/T/ipykernel_35258/929304889.py:24: DeprecationWarning:
Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
/var/folders/b3/g26r0dcx4b35vf3nk31216hc0000gr/T/ipykernel_35258/929304889.py:24: DeprecationWarning:
Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
Problem with one-hot encoding#
We would like the word representation to capture the similarity between tall and height and so we would like them to have bigger dot product or bigger cosine similarity (normalized dot product).
The problem with one-hot representation of words is that there is no inherent notion of relationship between words and the dot product between similar and non-similar words is zero.
Need a representation that captures relationships between words.#
We will be looking at two such representations.
Sparse representation with term-term co-occurrence matrix
Dense representation with word2vec
Both are based on the idea of distributional hypothesis
Distributional hypothesis#
You shall know a word by the company it keeps.
If A and B have almost identical environments we say that they are synonyms.
Example:
Her child loves to play in the playground.
Her kid loves to play in the playground.
Term-term co-occurrence matrix#
So far we have been talking about documents and we created document-term co-occurrence matrix (e.g., bag-of-words representation of text).
We can also do this with words. The idea is to go through a corpus of text, keeping a count of all of the words that appear in context of each word (within a window).
An example:
(Credit: Jurafsky and Martin 3rd edition)
Visualizing word vectors and similarity#
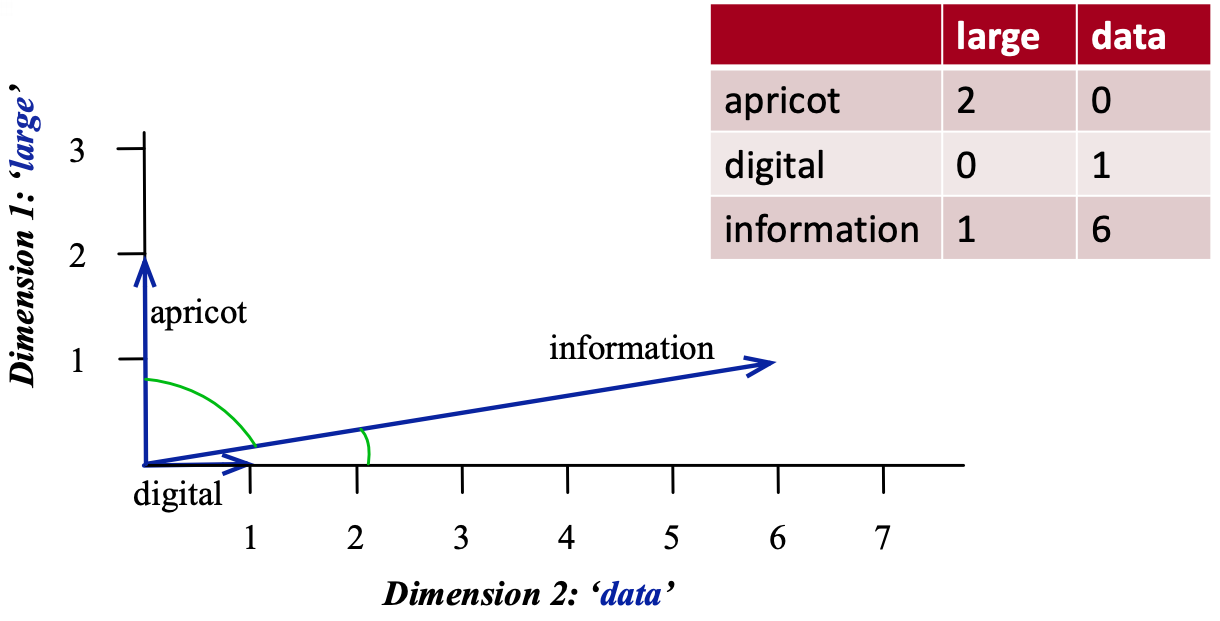
(Credit: Jurafsky and Martin 3rd edition)
The similarity is calculated using dot products between word vectors.
Example: \(\vec{\text{digital}}.\vec{\text{information}} = 0 \times 1 + 1\times 6 = 6\)
Higher the dot product more similar the words.
Visualizing word vectors and similarity#
(Credit: Jurafsky and Martin 3rd edition)
The similarity is calculated using dot products between word vectors.
Example: \(\vec{\text{digital}}.\vec{\text{information}} = 0 \times 1 + 1\times 6 = 6\)
Higher the dot product more similar the words.
We can also calculate a normalized version of dot products. $\(similarity_{cosine}(w_1,w_2) = \frac{w_1.w_2}{\left\lVert w_1\right\rVert_2 \left\lVert w_2\right\rVert_2}\)$
corpus = [
"How tall is Machu Picchu?",
"Machu Picchu is 13.164 degrees south of the equator.",
"The official height of Machu Picchu is 2,430 m.",
"Machu Picchu is 80 kilometres (50 miles) northwest of Cusco.",
"It is 80 kilometres (50 miles) northwest of Cusco, on the crest of the mountain Machu Picchu, located about 2,430 metres (7,970 feet) above mean sea level, over 1,000 metres (3,300 ft) lower than Cusco, which has an elevation of 3,400 metres (11,200 ft).",
]
sents = MyPreprocessor(corpus)
cm = CooccurrenceMatrix(
sents, window_size=2
) # Let's build term-term co-occurrence matrix for our text.
comat = cm.fit_transform()
vocab = cm.get_feature_names()
df = pd.DataFrame(comat.todense(), columns=vocab, index=vocab, dtype=np.int8)
df.head()
| tall | machu | picchu | 13.164 | degrees | south | equator | official | height | 2,430 | ... | mean | sea | level | 1,000 | 3,300 | ft | lower | elevation | 3,400 | 11,200 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| tall | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| machu | 1 | 0 | 5 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| picchu | 1 | 5 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 2 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 13.164 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| degrees | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 32 columns
print_cosine_similarity(df, "tall", "height")
print_cosine_similarity(df, "tall", "official")
The dot product between tall and height: 2.00 and cosine similarity is: 0.82
The dot product between tall and official: 1.00 and cosine similarity is: 0.50
/var/folders/b3/g26r0dcx4b35vf3nk31216hc0000gr/T/ipykernel_35258/929304889.py:24: DeprecationWarning:
Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
/var/folders/b3/g26r0dcx4b35vf3nk31216hc0000gr/T/ipykernel_35258/929304889.py:24: DeprecationWarning:
Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
We are getting non-zero cosine similarity now and we are able to capture some similarities between words now.
That said similarities do not make much sense in the toy example above because we’re using a tiny corpus.
To find meaningful patterns of similarities between words, we need a large corpus.
Let’s try a bit larger corpus and check whether the similarities make sense.
import wikipedia
from nltk.tokenize import sent_tokenize, word_tokenize
corpus = []
queries = [
"Machu Picchu",
# "Everest",
"Sequoia sempervirens",
"President (country)",
"Politics Canada",
]
for i in range(len(queries)):
sents = sent_tokenize(wikipedia.page(queries[i]).content)
corpus.extend(sents)
print("Number of sentences in the corpus: ", len(corpus))
Number of sentences in the corpus: 691
sents = MyPreprocessor(corpus)
cm = CooccurrenceMatrix(sents)
comat = cm.fit_transform()
vocab = cm.get_feature_names()
df = pd.DataFrame(comat.todense(), columns=vocab, index=vocab, dtype=np.int8)
df
| machu | picchu | 15th-century | inca | citadel | located | eastern | cordillera | southern | peru | ... | comprehensive | overview | cbc | digital | archives | boondoggles | elephants | campaigning | compared | textbook | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| machu | 0 | 79 | 1 | 5 | 1 | 2 | 1 | 0 | 1 | 2 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| picchu | 79 | 0 | 1 | 6 | 3 | 1 | 1 | 0 | 1 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 15th-century | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| inca | 5 | 6 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| citadel | 1 | 3 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| boondoggles | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| elephants | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| campaigning | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| compared | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| textbook | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
4074 rows × 4074 columns
print_cosine_similarity(df, "tall", "height")
print_cosine_similarity(df, "tall", "south")
The dot product between tall and height: 21.00 and cosine similarity is: 0.36
The dot product between tall and south: 2.00 and cosine similarity is: 0.05
/var/folders/b3/g26r0dcx4b35vf3nk31216hc0000gr/T/ipykernel_35258/929304889.py:24: DeprecationWarning:
Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
/var/folders/b3/g26r0dcx4b35vf3nk31216hc0000gr/T/ipykernel_35258/929304889.py:24: DeprecationWarning:
Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
Dense representations#
Sparse vs. dense word vectors#
Term-term co-occurrence matrix representation is long and sparse.
length |V| is usually large (e.g., > 50,000)
most elements are zero
OK because there are efficient ways to deal with sparse matrices.
Alternative#
Learn short (~100 to 1000 dimensions) and dense vectors.
Short vectors are usually easier to train with ML models (less weights to train).
They may generalize better.
In practice they work much better!
Short and dense word embeddings#

We won’t really talk about how to create these embeddings.
If you are interested in knowing more details, I’ve a video on a popular algorithm called Word2Vec to create such embeddings. This is totally optional.
Pre-trained embeddings#
Training embeddings is computationally expensive
For typical corpora, the vocabulary size is greater than 100,000.
If the size of embeddings is 300, the number of parameters of the model is \(2 \times 30,000,000\).
So people have trained embeddings on huge corpora and made them available.
A number of pre-trained word embeddings are available. The most popular ones are:
-
trained on several corpora using the word2vec algorithm
-
pretrained embeddings for 12 languages
-
trained using the GloVe algorithm
published by Stanford University
fastText pre-trained embeddings for 294 languages
trained using the fastText algorithm
published by Facebook
Let’s try Google News pre-trained embeddings.
You can download pre-trained embeddings from their original source.
Gensimprovides an api to conveniently load them. You can installgensimas follows.conda install -c anaconda gensimBelow I am loading word vectors trained on Google News corpus using this api.
import gensim
import gensim.downloader as api
print(list(api.info()["models"].keys()))
['fasttext-wiki-news-subwords-300', 'conceptnet-numberbatch-17-06-300', 'word2vec-ruscorpora-300', 'word2vec-google-news-300', 'glove-wiki-gigaword-50', 'glove-wiki-gigaword-100', 'glove-wiki-gigaword-200', 'glove-wiki-gigaword-300', 'glove-twitter-25', 'glove-twitter-50', 'glove-twitter-100', 'glove-twitter-200', '__testing_word2vec-matrix-synopsis']
google_news_vectors = api.load('word2vec-google-news-300')
print("Size of vocabulary: ", len(google_news_vectors))
Size of vocabulary: 3000000
google_news_vectorsabove has 300 dimensional word vectors for 3,000,000 unique words/phrases from Google news.
What can we do with these word vectors?#
Let’s examine word vector for the word UBC.
google_news_vectors["UBC"][:20] # Representation of the word UBC
array([-0.3828125 , -0.18066406, 0.10644531, 0.4296875 , 0.21582031,
-0.10693359, 0.13476562, -0.08740234, -0.14648438, -0.09619141,
0.02807617, 0.01409912, -0.12890625, -0.21972656, -0.41210938,
-0.1875 , -0.11914062, -0.22851562, 0.19433594, -0.08642578],
dtype=float32)
google_news_vectors["UBC"].shape
(300,)
Indeed it is a short and a dense (we do not see any zeros) vector!
Finding similar words#
Given word \(w\), search in the vector space for the word closest to \(w\) as measured by cosine similarity.
google_news_vectors.most_similar("UBC")
[('UVic', 0.7886474132537842),
('SFU', 0.7588527202606201),
('Simon_Fraser', 0.7356573939323425),
('UFV', 0.6880435943603516),
('VIU', 0.6778583526611328),
('Kwantlen', 0.6771427989006042),
('UBCO', 0.6734487414360046),
('UPEI', 0.6731125712394714),
('UBC_Okanagan', 0.6709135174751282),
('Lakehead_University', 0.6622507572174072)]
google_news_vectors.most_similar("information")
[('info', 0.7363681793212891),
('infomation', 0.680029571056366),
('infor_mation', 0.6733848452568054),
('informaiton', 0.6639009118080139),
('informa_tion', 0.660125732421875),
('informationon', 0.633933424949646),
('informationabout', 0.6320980787277222),
('Information', 0.6186580657958984),
('informaion', 0.6093292236328125),
('details', 0.6063088178634644)]
If you want to extract all documents containing words similar to information, you could use this information.
Google News embeddings also support multi-word phrases.
google_news_vectors.most_similar("british_columbia")
[('alberta', 0.6111123561859131),
('canadian', 0.6086404919624329),
('ontario', 0.6031432747840881),
('erik', 0.5993571877479553),
('dominican_republic', 0.5925410389900208),
('costco', 0.5824530720710754),
('rhode_island', 0.5804311633110046),
('dreampharmaceuticals', 0.5755444169044495),
('canada', 0.5630921125411987),
('austin', 0.5623062252998352)]
Finding similarity scores between words#
google_news_vectors.similarity("Canada", "hockey")
0.27610135
google_news_vectors.similarity("Japan", "hockey")
0.001962782
word_pairs = [
("height", "tall"),
("height", "official"),
("pineapple", "mango"),
("pineapple", "juice"),
("sun", "robot"),
("GPU", "hummus"),
]
for pair in word_pairs:
print(
"The similarity between %s and %s is %0.3f"
% (pair[0], pair[1], google_news_vectors.similarity(pair[0], pair[1]))
)
The similarity between height and tall is 0.473
The similarity between height and official is 0.002
The similarity between pineapple and mango is 0.668
The similarity between pineapple and juice is 0.418
The similarity between sun and robot is 0.029
The similarity between GPU and hummus is 0.094
We are getting reasonable word similarity scores!!
Success of word2vec#
This analogy example often comes up when people talk about word2vec, which was used by the authors of this method.
MAN : KING :: WOMAN : ?
What is the word that is similar to WOMAN in the same sense as KING is similar to MAN?
Perform a simple algebraic operations with the vector representation of words. \(\vec{X} = \vec{\text{KING}} − \vec{\text{MAN}} + \vec{\text{WOMAN}}\)
Search in the vector space for the word closest to \(\vec{X}\) measured by cosine distance.

(Credit: Mikolov et al. 2013)
def analogy(word1, word2, word3, model=google_news_vectors):
"""
Returns analogy word using the given model.
Parameters
--------------
word1 : (str)
word1 in the analogy relation
word2 : (str)
word2 in the analogy relation
word3 : (str)
word3 in the analogy relation
model :
word embedding model
Returns
---------------
pd.dataframe
"""
print("%s : %s :: %s : ?" % (word1, word2, word3))
sim_words = model.most_similar(positive=[word3, word2], negative=[word1])
return pd.DataFrame(sim_words, columns=["Analogy word", "Score"])
analogy("man", "king", "woman")
man : king :: woman : ?
| Analogy word | Score | |
|---|---|---|
| 0 | queen | 0.711819 |
| 1 | monarch | 0.618967 |
| 2 | princess | 0.590243 |
| 3 | crown_prince | 0.549946 |
| 4 | prince | 0.537732 |
| 5 | kings | 0.523684 |
| 6 | Queen_Consort | 0.523595 |
| 7 | queens | 0.518113 |
| 8 | sultan | 0.509859 |
| 9 | monarchy | 0.508741 |
analogy("Montreal", "Canadiens", "Vancouver")
Montreal : Canadiens :: Vancouver : ?
| Analogy word | Score | |
|---|---|---|
| 0 | Canucks | 0.821326 |
| 1 | Vancouver_Canucks | 0.750401 |
| 2 | Calgary_Flames | 0.705470 |
| 3 | Leafs | 0.695783 |
| 4 | Maple_Leafs | 0.691617 |
| 5 | Thrashers | 0.687504 |
| 6 | Avs | 0.681716 |
| 7 | Sabres | 0.665307 |
| 8 | Blackhawks | 0.664625 |
| 9 | Habs | 0.661023 |
analogy("Toronto", "UofT", "Vancouver")
Toronto : UofT :: Vancouver : ?
| Analogy word | Score | |
|---|---|---|
| 0 | SFU | 0.579245 |
| 1 | UVic | 0.576921 |
| 2 | UBC | 0.571431 |
| 3 | Simon_Fraser | 0.543464 |
| 4 | Langara_College | 0.541347 |
| 5 | UVIC | 0.520495 |
| 6 | Grant_MacEwan | 0.517273 |
| 7 | UFV | 0.514150 |
| 8 | Ubyssey | 0.510421 |
| 9 | Kwantlen | 0.503807 |
analogy("Gauss", "Mathematician", "Bob_Dylan")
Gauss : Mathematician :: Bob_Dylan : ?
| Analogy word | Score | |
|---|---|---|
| 0 | singer_songwriter_Bob_Dylan | 0.505507 |
| 1 | Johnny_Cash | 0.495035 |
| 2 | Randy_VanWarmer | 0.490558 |
| 3 | Heard_Voices | 0.487652 |
| 4 | Legendary_singer_songwriter | 0.484667 |
| 5 | Pete_Seeger | 0.478709 |
| 6 | Joan_Baez | 0.476631 |
| 7 | Tillie_Olsen | 0.476463 |
| 8 | Snooky_Pryor | 0.474850 |
| 9 | Receive_Honorary_Doctorate | 0.472724 |
analogy("USA", "pizza", "Japan")
USA : pizza :: Japan : ?
| Analogy word | Score | |
|---|---|---|
| 0 | sushi | 0.573410 |
| 1 | bento | 0.549762 |
| 2 | yakiniku | 0.536980 |
| 3 | okonomiyaki | 0.525135 |
| 4 | ramen | 0.520394 |
| 5 | gyudon | 0.515915 |
| 6 | soba | 0.513071 |
| 7 | ramen_noodle | 0.506992 |
| 8 | pepperoni_pizza | 0.495575 |
| 9 | yakitori | 0.489174 |
analogy("USA", "pizza", "India") # Just for fun
USA : pizza :: India : ?
| Analogy word | Score | |
|---|---|---|
| 0 | vada_pav | 0.554463 |
| 1 | jalebi | 0.547090 |
| 2 | idlis | 0.540039 |
| 3 | pav_bhaji | 0.526046 |
| 4 | dosas | 0.521772 |
| 5 | samosa | 0.520700 |
| 6 | idli | 0.516858 |
| 7 | pizzas | 0.516199 |
| 8 | tiffin | 0.514347 |
| 9 | chaat | 0.508534 |
Vada pav#

So you can imagine these models being useful in many meaning-related tasks.
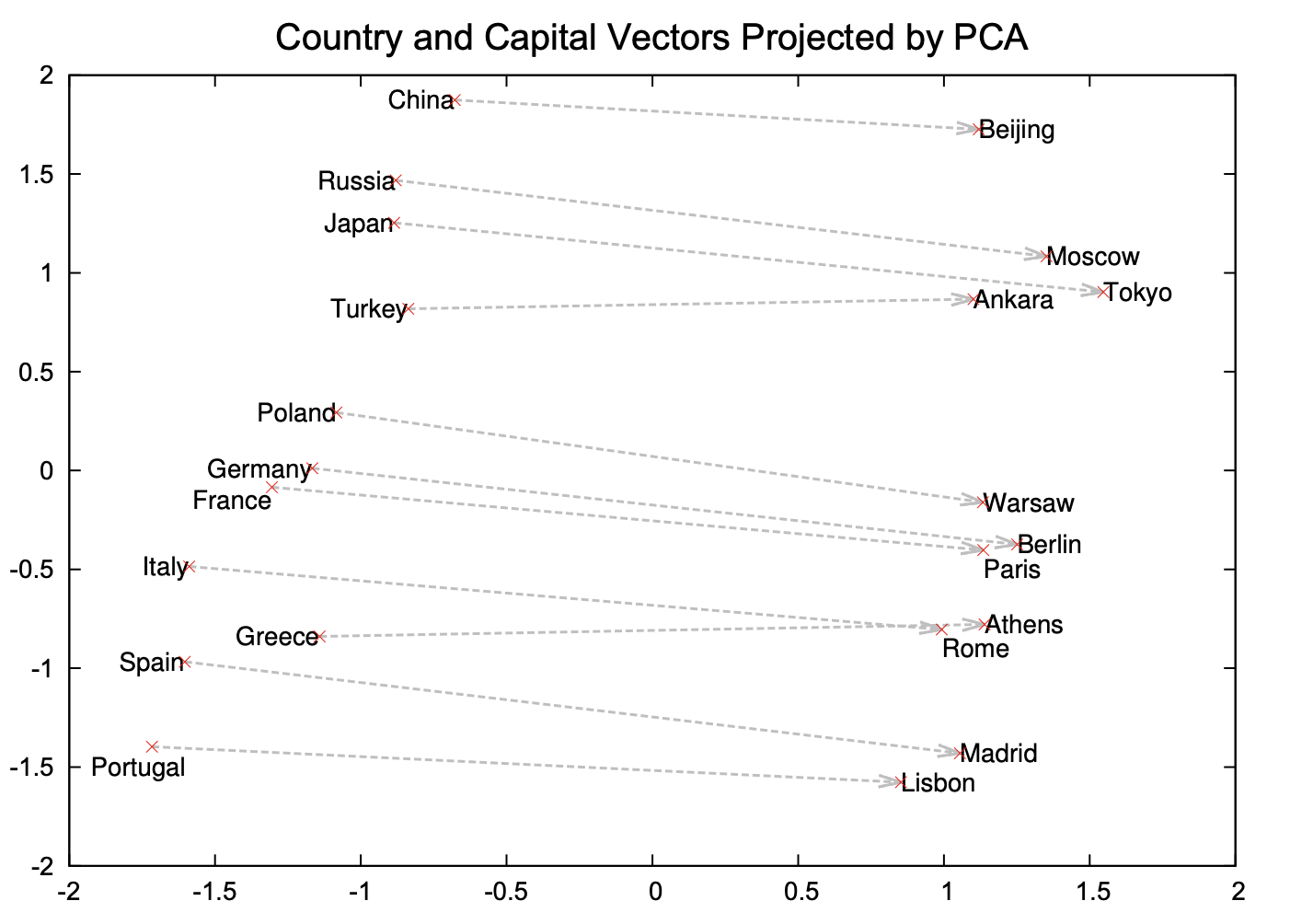
(Credit: Mikolov et al. 2013)
Examples of semantic and syntactic relationships#
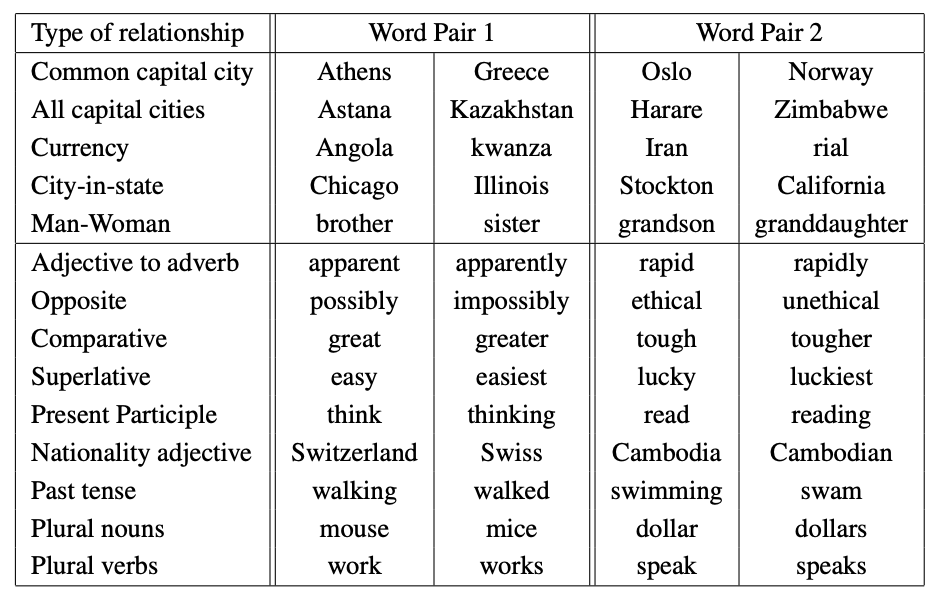
(Credit: Mikolov 2013)
Implicit biases and stereotypes in word embeddings#
analogy("man", "computer_programmer", "woman")
man : computer_programmer :: woman : ?
| Analogy word | Score | |
|---|---|---|
| 0 | homemaker | 0.562712 |
| 1 | housewife | 0.510505 |
| 2 | graphic_designer | 0.505180 |
| 3 | schoolteacher | 0.497949 |
| 4 | businesswoman | 0.493489 |
| 5 | paralegal | 0.492551 |
| 6 | registered_nurse | 0.490797 |
| 7 | saleswoman | 0.488163 |
| 8 | electrical_engineer | 0.479773 |
| 9 | mechanical_engineer | 0.475540 |

Embeddings reflect gender stereotypes present in broader society.
They may also amplify these stereotypes because of their widespread usage.
See the paper Man is to Computer Programmer as Woman is to ….
Most of the modern embeddings are de-biased for some obvious biases.
Note
Please be aware that these pre-trained word vectors are quite large in size (several gigabytes).
Word vectors with spaCy#
spaCy also gives you access to word vectors with bigger models:
en_core_web_mdoren_core_web_lrspaCy’s pre-trained embeddings are trained on OntoNotes corpus.This corpus has a collection of different styles of texts such as telephone conversations, newswire, newsgroups, broadcast news, broadcast conversation, weblogs, religious texts.
Let’s try it out.
import spacy
nlp = spacy.load("en_core_web_md")
doc = nlp("pineapple") # extract all interesting information about the document
doc.vector[:10]
array([ 0.65486 , -2.2584 , 0.062793, 1.8801 , 0.207 , -3.3299 ,
-0.96833 , 1.5131 , -3.7041 , -0.077749], dtype=float32)
doc.vector.shape
(300,)
Representing documents using word embeddings#
Assuming that we have reasonable representations of words.
How do we represent meaning of paragraphs or documents?
Two simple approaches
Averaging embeddings
Concatenating embeddings
Averaging embeddings#
All empty promises
\((embedding(all) + embedding(empty) + embedding(promise))/3\)
Average embeddings with spaCy#
We can do this conveniently with spaCy.
We need
en_core_web_mdmodel to access word vectors.You can download the model by going to command line and in your course
condaenvironment and downloaden_core_web_mdas follows.
conda activate cpsc330
python -m spacy download en_core_web_md
We can access word vectors for individual words in spaCy as follows.
We can get average embeddings for a sentence or a document in spaCy as follows:
s = "All empty promises"
doc = nlp(s)
avg_sent_emb = doc.vector
print(avg_sent_emb.shape)
print("Vector for: {}\n{}".format((s), (avg_sent_emb[0:10])))
(300,)
Vector for: All empty promises
[-0.459937 1.9785299 1.0319 1.5123 1.4806334 2.73183
1.204 1.1724668 -3.5227966 -0.05656664]
Check out Appendix_B to see an example of using these embeddings for text classification.
Break (5 min)#

Topic modeling#
Why topic modeling?#
Topic modeling introduction activity (~5 mins)#
Consider the following documents.
toy_df = pd.read_csv("data/toy_clustering.csv")
toy_df
| text | |
|---|---|
| 0 | famous fashion model |
| 1 | elegant fashion model |
| 2 | fashion model at famous probabilistic topic mo... |
| 3 | fresh elegant fashion model |
| 4 | famous elegant fashion model |
| 5 | probabilistic conference |
| 6 | creative probabilistic model |
| 7 | model diet apple kiwi nutrition |
| 8 | probabilistic model |
| 9 | kiwi health nutrition |
| 10 | fresh apple kiwi health diet |
| 11 | health nutrition |
| 12 | fresh apple kiwi juice nutrition |
| 13 | probabilistic topic model conference |
| 14 | probabilistic topi model |
Discuss the following questions with your neighbour and write your answers in this Google doc.
Suppose you are asked to cluster these documents manually. How many clusters would you identify?
What are the prominent words in each cluster?
Are there documents which are a mixture of multiple clusters?
Topic modeling motivation#
Humans are pretty good at reading and understanding a document and answering questions such as
What is it about?
Which documents is it related to?
What if you’re given a large collection of documents on a variety of topics.
Example: A corpus of news articles#
Example: A corpus of food magazines#
A corpus of scientific articles#

(Credit: Dave Blei’s presentation)
It would take years to read all documents and organize and categorize them so that they are easy to search.
You need an automated way
to get an idea of what’s going on in the data or
to pull documents related to a certain topic
Topic modeling gives you an ability to summarize the major themes in a large collection of documents (corpus).
Example: The major themes in a collection of news articles could be
politics
entertainment
sports
technology
…
Topic modeling is a great EDA tool to get a sense of what’s going on in a large corpus.
Some examples
If you want to pull documents related to a particular lawsuit.
You want to examine people’s sentiment towards a particular candidate and/or political party and so you want to pull tweets or Facebook posts related to election.
How do you do topic modeling?#
A common tool to solve such problems is unsupervised ML methods.
Given the hyperparameter \(K\), the goal of topic modeling is to describe a set of documents using \(K\) “topics”.
In unsupervised setting, the input of topic modeling is
A large collection of documents
A value for the hyperparameter \(K\) (e.g., \(K = 3\))
and the output is
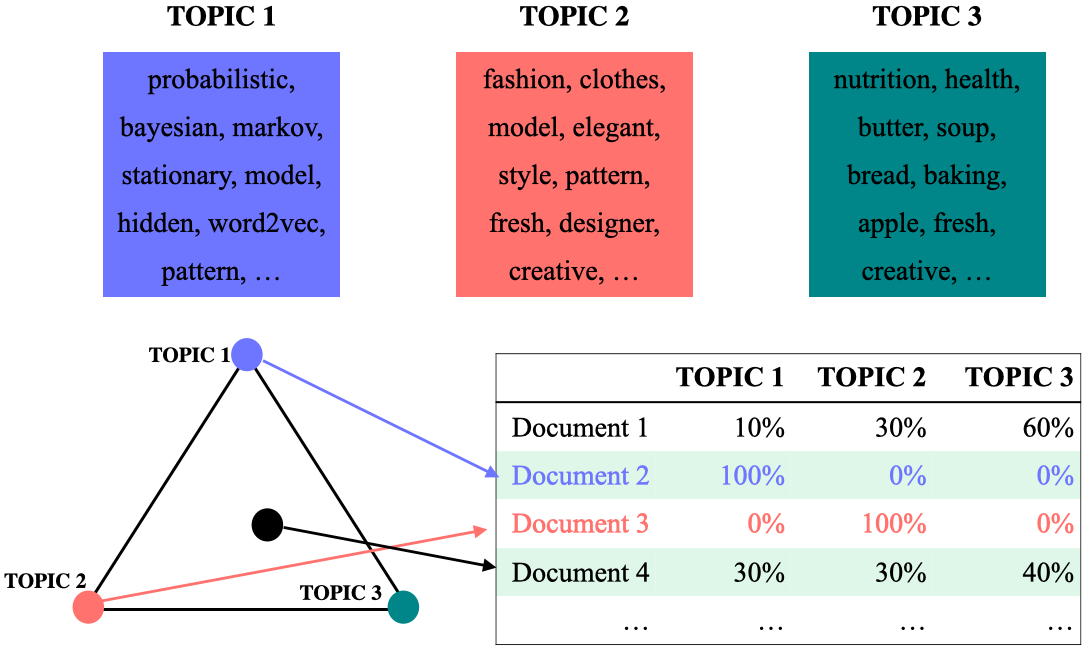
Topic-words association
For each topic, what words describe that topic?
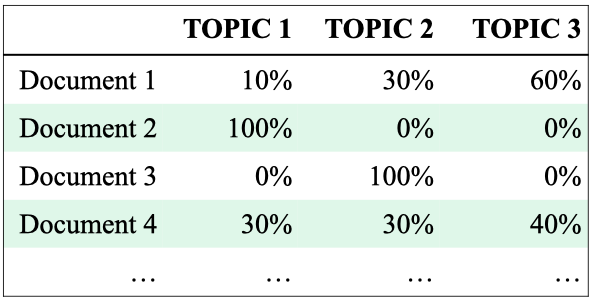
Document-topics association
For each document, what topics are expressed by the document?
Topic modeling: Example#
Topic-words association
For each topic, what words describe that topic?
A topic is a mixture of words.

Topic modeling: Example#
Document-topics association
For each document, what topics are expressed by the document?
A document is a mixture of topics.
Topic modeling: Input and output#
Input
A large collection of documents
A value for the hyperparameter \(K\) (e.g., \(K = 3\))
Output
For each topic, what words describe that topic?
For each document, what topics are expressed by the document?
Topic modeling: Some applications#
Topic modeling is a great EDA tool to get a sense of what’s going on in a large corpus.
Some examples
If you want to pull documents related to a particular lawsuit.
You want to examine people’s sentiment towards a particular candidate and/or political party and so you want to pull tweets or Facebook posts related to election.
Topic modeling examples#
Topic modeling: Input#
Credit: David Blei’s presentation
Topic modeling: output#

(Credit: David Blei’s presentation)
Topic modeling: output with interpretation#
Assigning labels is a human thing.
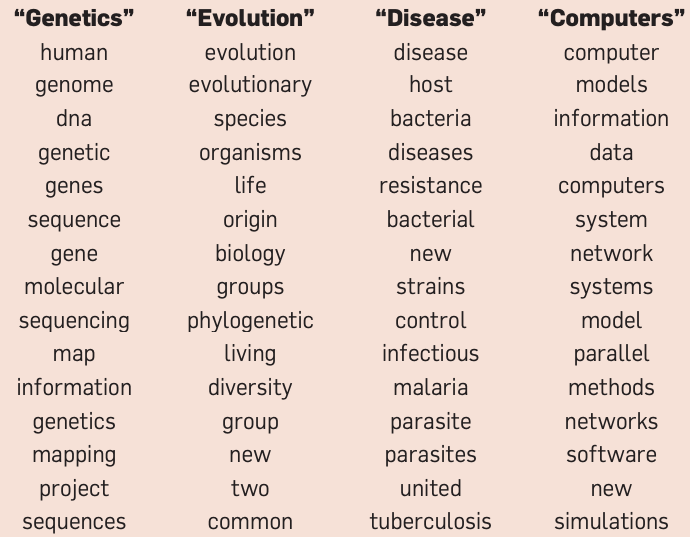
(Credit: David Blei’s presentation)
LDA topics in Yale Law Journal#

(Credit: David Blei’s paper)
LDA topics in social media#
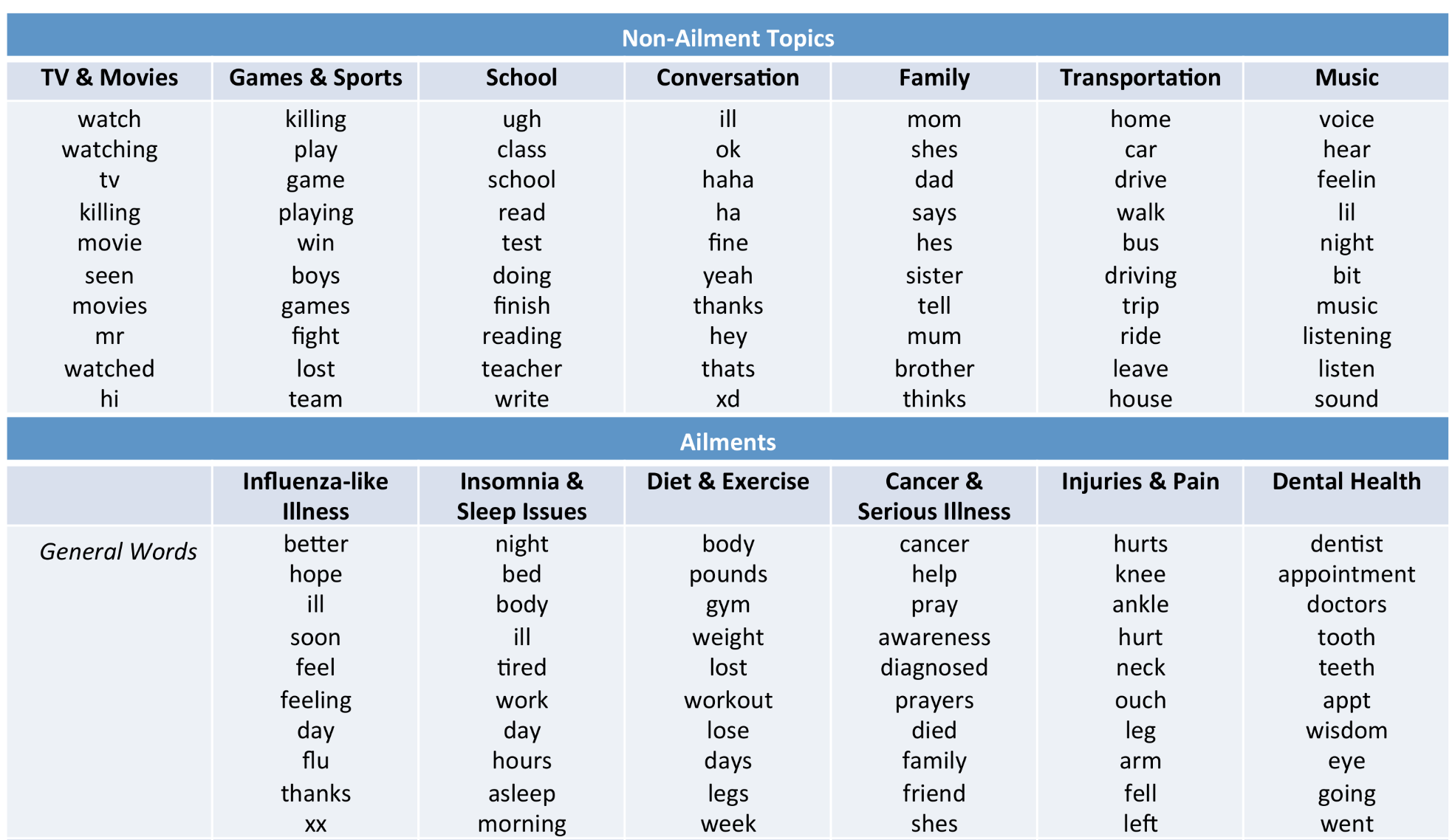
(Credit: Health topics in social media)
Based on the tools in your toolbox what would you use for topic modeling?
In this lecture, I will demonstrate how to perform topic modeling using the Latent Dirichlet Allocation model implemented in sklearn. We won’t delve into the inner workings of the model, as it falls outside the scope of this course. Instead, our objective is to understand how to apply it to your specific problems and comprehend the model’s input and output.
Topic modeling toy example#
Let’s work with a toy example.
toy_df = pd.read_csv("data/toy_lda_data.csv")
toy_df
| doc_id | text | |
|---|---|---|
| 0 | 1 | famous fashion model |
| 1 | 2 | fashion model pattern |
| 2 | 3 | fashion model probabilistic topic model confer... |
| 3 | 4 | famous fashion model |
| 4 | 5 | fresh fashion model |
| 5 | 6 | famous fashion model |
| 6 | 7 | famous fashion model |
| 7 | 8 | famous fashion model |
| 8 | 9 | famous fashion model |
| 9 | 10 | creative fashion model |
| 10 | 11 | famous fashion model |
| 11 | 12 | famous fashion model |
| 12 | 13 | fashion model probabilistic topic model confer... |
| 13 | 14 | probabilistic topic model |
| 14 | 15 | probabilistic model pattern |
| 15 | 16 | probabilistic topic model |
| 16 | 17 | probabilistic topic model |
| 17 | 18 | probabilistic topic model |
| 18 | 19 | probabilistic topic model |
| 19 | 20 | probabilistic topic model |
| 20 | 21 | probabilistic topic model |
| 21 | 22 | fashion model probabilistic topic model confer... |
| 22 | 23 | apple kiwi nutrition |
| 23 | 24 | kiwi health nutrition |
| 24 | 25 | fresh apple health |
| 25 | 26 | probabilistic topic model |
| 26 | 27 | creative health nutrition |
| 27 | 28 | probabilistic topic model |
| 28 | 29 | probabilistic topic model |
| 29 | 30 | hidden markov model probabilistic |
| 30 | 31 | probabilistic topic model |
| 31 | 32 | probabilistic topic model |
| 32 | 33 | apple kiwi nutrition |
| 33 | 34 | apple kiwi health |
| 34 | 35 | apple kiwi nutrition |
| 35 | 36 | fresh kiwi health |
| 36 | 37 | apple kiwi nutrition |
| 37 | 38 | apple kiwi nutrition |
| 38 | 39 | apple kiwi nutrition |
Input to the LDA topic model is bag-of-words representation of text.
Let’s create bag-of-words representation of “text” column.
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(stop_words="english")
toy_X = vec.fit_transform(toy_df["text"])
toy_X
<39x15 sparse matrix of type '<class 'numpy.int64'>'
with 124 stored elements in Compressed Sparse Row format>
vocab = vec.get_feature_names_out() # vocabulary
vocab
array(['apple', 'conference', 'creative', 'famous', 'fashion', 'fresh',
'health', 'hidden', 'kiwi', 'markov', 'model', 'nutrition',
'pattern', 'probabilistic', 'topic'], dtype=object)
len(vocab)
15
Let’s try to create a topic model with sklearn’s LatentDirichletAllocation.
from sklearn.decomposition import LatentDirichletAllocation
n_topics = 3 # number of topics
lda = LatentDirichletAllocation(
n_components=n_topics, learning_method="batch", max_iter=10, random_state=0
)
lda.fit(toy_X)
document_topics = lda.transform(toy_X)
Once we have a fitted model we can get the word-topic association and document-topic association
Word-topic association
lda.components_gives us the weights associated with each word for each topic. In other words, it tells us which word is important for which topic.
Document-topic association
Calling transform on the data gives us document-topic association.
lda.components_
array([[ 0.33380754, 3.31038074, 0.33476534, 0.33397112, 0.36695134,
0.33439238, 0.33381373, 0.35771821, 0.33380649, 0.35771821,
17.78521263, 0.33380761, 0.3573886 , 17.31634363, 15.32791718],
[ 8.33224516, 0.33400489, 2.2173627 , 0.33411086, 0.33732465,
3.28753559, 5.33223002, 0.33435326, 9.33224759, 0.33435326,
0.33797555, 8.3322447 , 0.33462759, 0.33440682, 0.33425967],
[ 0.3339473 , 0.35561437, 0.44787197, 8.33191802, 14.29572402,
0.37807203, 0.33395626, 1.30792853, 0.33394593, 1.30792853,
13.87681182, 0.33394769, 2.30798381, 0.34924955, 0.33782315]])
print("lda.components_.shape: {}".format(lda.components_.shape))
lda.components_.shape: (3, 15)
import plotly.express as px
plot_lda_w_vectors(lda.components_, ['topic 0', 'topic 1', 'topic 2'], vocab, width=800, height=600)
Let’s look at the words with highest weights for each topic more systematically.
np.argsort(lda.components_, axis=1)
array([[ 8, 0, 11, 6, 3, 5, 2, 12, 7, 9, 4, 1, 14, 13, 10],
[ 1, 3, 14, 7, 9, 13, 12, 4, 10, 2, 5, 6, 11, 0, 8],
[ 8, 0, 11, 6, 14, 13, 1, 5, 2, 9, 7, 12, 3, 10, 4]])
sorting = np.argsort(lda.components_, axis=1)[:, ::-1]
feature_names = np.array(vec.get_feature_names_out())
import mglearn
mglearn.tools.print_topics(
topics=range(3),
feature_names=feature_names,
sorting=sorting,
topics_per_chunk=5,
n_words=10,
)
topic 0 topic 1 topic 2
-------- -------- --------
model kiwi fashion
probabilistic apple model
topic nutrition famous
conference health pattern
fashion fresh hidden
markov creative markov
hidden model creative
pattern fashion fresh
creative pattern conference
fresh probabilistic probabilistic
Here is how we can interpret the topics
Topic 0 \(\rightarrow\) ML modeling
Topic 1 \(\rightarrow\) fruit and nutrition
Topic 2 \(\rightarrow\) fashion
Let’s look at distribution of topics for a document
toy_df.iloc[0]['text']
'famous fashion model'
document_topics[0]
array([0.08791477, 0.08338644, 0.82869879])
This document is made up of
~83% topic 2
~9% topic 0
~8% topic 1.
Topic modeling pipeline#
Above we worked with toy data. In the real world, we usually need to preprocess the data before passing it to LDA.
Here are typical steps if you want to carry out topic modeling on real-world data.
Preprocess your corpus.
Train LDA.
Interpret your topics.
Data#
import wikipedia
queries = [
"Artificial Intelligence",
"unsupervised learning",
"Supreme Court of Canada",
"Peace, Order, and Good Government",
"Canadian constitutional law",
"ice hockey",
]
wiki_dict = {"wiki query": [], "text": []}
for i in range(len(queries)):
wiki_dict["text"].append(wikipedia.page(queries[i]).content)
wiki_dict["wiki query"].append(queries[i])
wiki_df = pd.DataFrame(wiki_dict)
wiki_df
| wiki query | text | |
|---|---|---|
| 0 | Artificial Intelligence | Artificial intelligence (AI) is the intelligen... |
| 1 | unsupervised learning | Supervised learning (SL) is a paradigm in mach... |
| 2 | Supreme Court of Canada | The Supreme Court of Canada (SCC; French: Cour... |
| 3 | Peace, Order, and Good Government | In many Commonwealth jurisdictions, the phrase... |
| 4 | Canadian constitutional law | Canadian constitutional law (French: droit con... |
| 5 | ice hockey | Ice hockey (or simply hockey) is a team sport ... |
Preprocessing the corpus#
Preprocessing is crucial!
Tokenization, converting text to lower case
Removing punctuation and stopwords
Discarding words with length < threshold or word frequency < threshold
Possibly lemmatization: Consider the lemmas instead of inflected forms.
Depending upon your application, restrict to specific part of speech;
For example, only consider nouns, verbs, and adjectives
We’ll use spaCy for preprocessing. Check out available token attributes here.
import spacy
nlp = spacy.load("en_core_web_md", disable=["parser", "ner"])
def preprocess(
doc,
min_token_len=2,
irrelevant_pos=["ADV", "PRON", "CCONJ", "PUNCT", "PART", "DET", "ADP", "SPACE"],
):
"""
Given text, min_token_len, and irrelevant_pos carry out preprocessing of the text
and return a preprocessed string.
Parameters
-------------
doc : (spaCy doc object)
the spacy doc object of the text
min_token_len : (int)
min_token_length required
irrelevant_pos : (list)
a list of irrelevant pos tags
Returns
-------------
(str) the preprocessed text
"""
clean_text = []
for token in doc:
if (
token.is_stop == False # Check if it's not a stopword
and len(token) > min_token_len # Check if the word meets minimum threshold
and token.pos_ not in irrelevant_pos
): # Check if the POS is in the acceptable POS tags
lemma = token.lemma_ # Take the lemma of the word
clean_text.append(lemma.lower())
return " ".join(clean_text)
wiki_df["text_pp"] = [preprocess(text) for text in nlp.pipe(wiki_df["text"])]
wiki_df
| wiki query | text | text_pp | |
|---|---|---|---|
| 0 | Artificial Intelligence | Artificial intelligence (AI) is the intelligen... | artificial intelligence intelligence machine s... |
| 1 | unsupervised learning | Supervised learning (SL) is a paradigm in mach... | supervised learning paradigm machine learning ... |
| 2 | Supreme Court of Canada | The Supreme Court of Canada (SCC; French: Cour... | supreme court canada scc french cour suprême c... |
| 3 | Peace, Order, and Good Government | In many Commonwealth jurisdictions, the phrase... | commonwealth jurisdiction phrase peace order g... |
| 4 | Canadian constitutional law | Canadian constitutional law (French: droit con... | canadian constitutional law french droit const... |
| 5 | ice hockey | Ice hockey (or simply hockey) is a team sport ... | ice hockey hockey team sport play ice skate ic... |
Topic modeling with sklearn#
We are using
GensimLDA because it’s more flexible.But we can also train an LDA model with
sklearn.
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(stop_words='english')
X = vec.fit_transform(wiki_df["text_pp"])
from sklearn.decomposition import LatentDirichletAllocation
n_topics = 3
lda = LatentDirichletAllocation(
n_components=n_topics, learning_method="batch", max_iter=10, random_state=0
)
document_topics = lda.fit_transform(X)
print("lda.components_.shape: {}".format(lda.components_.shape))
lda.components_.shape: (3, 3685)
sorting = np.argsort(lda.components_, axis=1)[:, ::-1]
feature_names = np.array(vec.get_feature_names_out())
import mglearn
mglearn.tools.print_topics(
topics=range(3),
feature_names=feature_names,
sorting=sorting,
topics_per_chunk=5,
n_words=10,
)
topic 0 topic 1 topic 2
-------- -------- --------
hockey displaystyle court
ice algorithm law
player function provincial
team learn government
play training power
league learning federal
game datum canada
puck input justice
penalty feature case
intelligence variance supreme
Check out some recent topic modeling tools
Basic text preprocessing [video]#
Introduction#
Why do we need preprocessing?
Text data is unstructured and messy.
We need to “normalize” it before we do anything interesting with it.
Example:
Lemma: Same stem, same part-of-speech, roughly the same meaning
Vancouver’s → Vancouver
computers → computer
rising → rise, rose, rises
Tokenization#
Sentence segmentation
Split text into sentences
Word tokenization
Split sentences into words
Tokenization: sentence segmentation#
MDS is a Master's program at UBC in British Columbia. MDS teaching team is truly multicultural!! Dr. George did his Ph.D. in Scotland. Dr. Timbers, Dr. Ostblom, Dr. Rodríguez-Arelis, and Dr. Kolhatkar did theirs in Canada. Dr. Gelbart did his PhD in the U.S.
How many sentences are there in this text?
### Let's do sentence segmentation on "."
text = (
"MDS is a Master's program at UBC in British Columbia. "
"MDS teaching team is truly multicultural!! "
"Dr. George did his Ph.D. in Scotland. "
"Dr. Timbers, Dr. Ostblom, Dr. Rodríguez-Arelis, and Dr. Kolhatkar did theirs in Canada. "
"Dr. Gelbart did his PhD in the U.S."
)
print(text.split("."))
["MDS is a Master's program at UBC in British Columbia", ' MDS teaching team is truly multicultural!! Dr', ' George did his Ph', 'D', ' in Scotland', ' Dr', ' Timbers, Dr', ' Ostblom, Dr', ' Rodríguez-Arelis, and Dr', ' Kolhatkar did theirs in Canada', ' Dr', ' Gelbart did his PhD in the U', 'S', '']
Sentence segmentation#
In English, period (.) is quite ambiguous. (In Chinese, it is unambiguous.)
Abbreviations like Dr., U.S., Inc.
Numbers like 60.44%, 0.98
! and ? are relatively ambiguous.
How about writing regular expressions?
A common way is using off-the-shelf models for sentence segmentation.
### Let's try to do sentence segmentation using nltk
from nltk.tokenize import sent_tokenize
sent_tokenized = sent_tokenize(text)
print(sent_tokenized)
["MDS is a Master's program at UBC in British Columbia.", 'MDS teaching team is truly multicultural!!', 'Dr. George did his Ph.D. in Scotland.', 'Dr. Timbers, Dr. Ostblom, Dr. Rodríguez-Arelis, and Dr. Kolhatkar did theirs in Canada.', 'Dr. Gelbart did his PhD in the U.S.']
Word tokenization#
MDS is a Master's program at UBC in British Columbia.
How many words are there in this sentence?
Is whitespace a sufficient condition for a word boundary?
Word tokenization#
MDS is a Master's program at UBC in British Columbia.
What’s our definition of a word?
Should British Columbia be one word or two words?
Should punctuation be considered a separate word?
What about the punctuations in
U.S.?What do we do with words like
Master's?
This process of identifying word boundaries is referred to as tokenization.
You can use regex but better to do it with off-the-shelf ML models.
### Let's do word segmentation on white spaces
print("Splitting on whitespace: ", [sent.split() for sent in sent_tokenized])
### Let's try to do word segmentation using nltk
from nltk.tokenize import word_tokenize
word_tokenized = [word_tokenize(sent) for sent in sent_tokenized]
# This is similar to the input format of word2vec algorithm
print("\n\n\nTokenized: ", word_tokenized)
Splitting on whitespace: [['MDS', 'is', 'a', "Master's", 'program', 'at', 'UBC', 'in', 'British', 'Columbia.'], ['MDS', 'teaching', 'team', 'is', 'truly', 'multicultural!!'], ['Dr.', 'George', 'did', 'his', 'Ph.D.', 'in', 'Scotland.'], ['Dr.', 'Timbers,', 'Dr.', 'Ostblom,', 'Dr.', 'Rodríguez-Arelis,', 'and', 'Dr.', 'Kolhatkar', 'did', 'theirs', 'in', 'Canada.'], ['Dr.', 'Gelbart', 'did', 'his', 'PhD', 'in', 'the', 'U.S.']]
Tokenized: [['MDS', 'is', 'a', 'Master', "'s", 'program', 'at', 'UBC', 'in', 'British', 'Columbia', '.'], ['MDS', 'teaching', 'team', 'is', 'truly', 'multicultural', '!', '!'], ['Dr.', 'George', 'did', 'his', 'Ph.D.', 'in', 'Scotland', '.'], ['Dr.', 'Timbers', ',', 'Dr.', 'Ostblom', ',', 'Dr.', 'Rodríguez-Arelis', ',', 'and', 'Dr.', 'Kolhatkar', 'did', 'theirs', 'in', 'Canada', '.'], ['Dr.', 'Gelbart', 'did', 'his', 'PhD', 'in', 'the', 'U.S', '.']]
Word segmentation#
For some languages you need much more sophisticated tokenizers.
For languages such as Chinese, there are no spaces between words.
jieba is a popular tokenizer for Chinese.
German doesn’t separate compound words.
Example: rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz
(the law for the delegation of monitoring beef labeling)
Types and tokens#
Usually in NLP, we talk about
Type an element in the vocabulary
Token an instance of that type in running text
Exercise for you#
UBC is located in the beautiful province of British Columbia. It's very close to the U.S. border. You'll get to the USA border in about 45 mins by car.
Consider the example above.
How many types? (task dependent)
How many tokens?
Other commonly used preprocessing steps#
Punctuation and stopword removal
Stemming and lemmatization
Punctuation and stopword removal#
The most frequently occurring words in English are not very useful in many NLP tasks.
Example: the , is , a , and punctuation
Probably not very informative in many tasks
# Let's use `nltk.stopwords`.
# Add punctuations to the list.
stop_words = list(set(stopwords.words("english")))
import string
punctuation = string.punctuation
stop_words += list(punctuation)
# stop_words.extend(['``','`','br','"',"”", "''", "'s"])
print(stop_words)
['that', 'and', 'or', 'been', 'once', 'needn', 'it', 'ain', "shan't", 'the', 'now', 'into', 'a', "wouldn't", 'few', 'doesn', 'having', 'don', "aren't", 'had', "needn't", "it's", 'was', 'those', 'whom', 'did', 'as', 'than', 'each', 'o', "mustn't", 're', 'up', "isn't", 'are', 'because', 'but', 'all', "that'll", 'should', 'about', 'which', 'why', 'such', 'will', 'y', 'hasn', "hasn't", "couldn't", 'hers', 'wasn', 'over', "she's", 'through', "you've", 'with', 't', 'where', 'haven', 'myself', 'hadn', "didn't", 'you', 'our', 'ourselves', 'against', "doesn't", 'then', 'didn', 'there', 'to', 'itself', 'were', 'between', 'these', "should've", "haven't", 'just', 'wouldn', 'very', 'ma', "wasn't", 'themselves', 'both', 'yours', 'mightn', 'won', 'he', 'herself', 'during', "mightn't", 'nor', 'off', 'too', 'doing', 'this', 'them', 'down', 'again', 'll', 'for', 'isn', 'is', 'being', 'their', 'him', 'above', 'below', 'under', 'most', 'm', 'some', "you'll", 'when', 'her', "shouldn't", 'mustn', 'in', 'ours', 'own', 'his', 'not', 'she', 'can', 'does', 'am', 'no', 'who', 'we', 'do', "you're", 'himself', 'weren', 'yourselves', "weren't", 'how', 'on', 'while', "you'd", 'what', 'only', 'so', 's', 'me', 'yourself', 'd', 've', 'more', 'has', 'at', 'be', 'other', 'they', 'if', 'aren', "hadn't", 'same', 'couldn', "don't", 'of', 'until', 'i', 'its', 'your', 'out', 'shouldn', 'an', 'my', 'shan', "won't", 'have', 'any', 'further', 'here', 'before', 'by', 'after', 'theirs', 'from', '!', '"', '#', '$', '%', '&', "'", '(', ')', '*', '+', ',', '-', '.', '/', ':', ';', '<', '=', '>', '?', '@', '[', '\\', ']', '^', '_', '`', '{', '|', '}', '~']
### Get rid of stop words
preprocessed = []
for sent in word_tokenized:
for token in sent:
token = token.lower()
if token not in stop_words:
preprocessed.append(token)
print(preprocessed)
['mds', 'master', "'s", 'program', 'ubc', 'british', 'columbia', 'mds', 'teaching', 'team', 'truly', 'multicultural', 'dr.', 'george', 'ph.d.', 'scotland', 'dr.', 'timbers', 'dr.', 'ostblom', 'dr.', 'rodríguez-arelis', 'dr.', 'kolhatkar', 'canada', 'dr.', 'gelbart', 'phd', 'u.s']
Lemmatization#
For many NLP tasks (e.g., web search) we want to ignore morphological differences between words
Example: If your search term is “studying for ML quiz” you might want to include pages containing “tips to study for an ML quiz” or “here is how I studied for my ML quiz”
Lemmatization converts inflected forms into the base form.
import nltk
nltk.download("wordnet")
[nltk_data] Downloading package wordnet to /Users/kvarada/nltk_data...
[nltk_data] Package wordnet is already up-to-date!
True
nltk.download('omw-1.4')
[nltk_data] Downloading package omw-1.4 to /Users/kvarada/nltk_data...
[nltk_data] Package omw-1.4 is already up-to-date!
True
# nltk has a lemmatizer
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print("Lemma of studying: ", lemmatizer.lemmatize("studying", "v"))
print("Lemma of studied: ", lemmatizer.lemmatize("studied", "v"))
Lemma of studying: study
Lemma of studied: study
Stemming#
Has a similar purpose but it is a crude chopping of affixes
automates, automatic, automation all reduced to automat.
Usually these reduced forms (stems) are not actual words themselves.
A popular stemming algorithm for English is PorterStemmer.
Beware that it can be aggressive sometimes.
from nltk.stem.porter import PorterStemmer
text = (
"UBC is located in the beautiful province of British Columbia... "
"It's very close to the U.S. border."
)
ps = PorterStemmer()
tokenized = word_tokenize(text)
stemmed = [ps.stem(token) for token in tokenized]
print("Before stemming: ", text)
print("\n\nAfter stemming: ", " ".join(stemmed))
Before stemming: UBC is located in the beautiful province of British Columbia... It's very close to the U.S. border.
After stemming: ubc is locat in the beauti provinc of british columbia ... it 's veri close to the u.s. border .
Other tools for preprocessing#
We used Natural Language Processing Toolkit (nltk) above
Many available tools
spaCy#
Industrial strength NLP library.
Lightweight, fast, and convenient to use.
spaCy does many things that we did above in one line of code!
Also has multi-lingual support.
import spacy
# Load the model
nlp = spacy.load("en_core_web_md")
text = (
"MDS is a Master's program at UBC in British Columbia. "
"MDS teaching team is truly multicultural!! "
"Dr. George did his Ph.D. in Scotland. "
"Dr. Timbers, Dr. Ostblom, Dr. Rodríguez-Arelis, and Dr. Kolhatkar did theirs in Canada. "
"Dr. Gelbart did his PhD in the U.S."
)
doc = nlp(text)
# Accessing tokens
tokens = [token for token in doc]
print("\nTokens: ", tokens)
# Accessing lemma
lemmas = [token.lemma_ for token in doc]
print("\nLemmas: ", lemmas)
# Accessing pos
pos = [token.pos_ for token in doc]
print("\nPOS: ", pos)
Tokens: [MDS, is, a, Master, 's, program, at, UBC, in, British, Columbia, ., MDS, teaching, team, is, truly, multicultural, !, !, Dr., George, did, his, Ph.D., in, Scotland, ., Dr., Timbers, ,, Dr., Ostblom, ,, Dr., Rodríguez, -, Arelis, ,, and, Dr., Kolhatkar, did, theirs, in, Canada, ., Dr., Gelbart, did, his, PhD, in, the, U.S.]
Lemmas: ['mds', 'be', 'a', 'Master', "'s", 'program', 'at', 'UBC', 'in', 'British', 'Columbia', '.', 'mds', 'teaching', 'team', 'be', 'truly', 'multicultural', '!', '!', 'Dr.', 'George', 'do', 'his', 'ph.d.', 'in', 'Scotland', '.', 'Dr.', 'Timbers', ',', 'Dr.', 'Ostblom', ',', 'Dr.', 'Rodríguez', '-', 'Arelis', ',', 'and', 'Dr.', 'Kolhatkar', 'do', 'theirs', 'in', 'Canada', '.', 'Dr.', 'Gelbart', 'do', 'his', 'phd', 'in', 'the', 'U.S.']
POS: ['NOUN', 'AUX', 'DET', 'PROPN', 'PART', 'NOUN', 'ADP', 'PROPN', 'ADP', 'PROPN', 'PROPN', 'PUNCT', 'NOUN', 'NOUN', 'NOUN', 'AUX', 'ADV', 'ADJ', 'PUNCT', 'PUNCT', 'PROPN', 'PROPN', 'VERB', 'PRON', 'NOUN', 'ADP', 'PROPN', 'PUNCT', 'PROPN', 'PROPN', 'PUNCT', 'PROPN', 'PROPN', 'PUNCT', 'PROPN', 'PROPN', 'PUNCT', 'PROPN', 'PUNCT', 'CCONJ', 'PROPN', 'PROPN', 'VERB', 'PRON', 'ADP', 'PROPN', 'PUNCT', 'PROPN', 'PROPN', 'VERB', 'PRON', 'NOUN', 'ADP', 'DET', 'PROPN']
Other typical NLP tasks#
In order to understand text, we usually are interested in extracting information from text. Some common tasks in NLP pipeline are:
Part of speech tagging
Assigning part-of-speech tags to all words in a sentence.
Named entity recognition
Labelling named “real-world” objects, like persons, companies or locations.
Coreference resolution
Deciding whether two strings (e.g., UBC vs University of British Columbia) refer to the same entity
Dependency parsing
Representing grammatical structure of a sentence
Extracting named-entities using spaCy#
from spacy import displacy
doc = nlp(
"University of British Columbia "
"is located in the beautiful "
"province of British Columbia."
)
displacy.render(doc, style="ent")
# Text and label of named entity span
print("Named entities:\n", [(ent.text, ent.label_) for ent in doc.ents])
print("\nORG means: ", spacy.explain("ORG"))
print("GPE means: ", spacy.explain("GPE"))
Named entities:
[('University of British Columbia', 'ORG'), ('British Columbia', 'GPE')]
ORG means: Companies, agencies, institutions, etc.
GPE means: Countries, cities, states
Dependency parsing using spaCy#
doc = nlp("I like cats")
displacy.render(doc, style="dep")
Many other things possible#
A powerful tool
All my Capstone groups last year used this tool.
You can build your own rule-based searches.
You can also access word vectors using spaCy with bigger models. (Currently we are using
en_core_web_mdmodel.)
Summary#
NLP is a big and very active field.
We broadly explored three topics:
Word embeddings using pretrained models
Topic modeling
Basic text preprocessing
Here are some resources if you want to get into NLP.
Check out this new CPSC course on NLP.
The first resource I would recommend is the following book by Jurafsky and Martin. It’s very approachable and fun. And the current edition is available online.
There is a course taught at Stanford called “From languages to Information” by one of the co-authors of the above book, and it might be a good introduction to NLP for you. Most of the course material and videos are available for free.
If you are into deep learning, you may refer to this course. Again, all lecture videos are available on youtube.
If you want to look at current advancements in the field, you’ll find all NLP related publications here.