
Lecture 8: Hyperparameter Optimization and Optimization Bias#
UBC 2023-24
Instructor: Varada Kolhatkar and Andrew Roth
Lecture plan#
iClicker questions from lecture 7
Parametric vs non-parametric models
Hyperparameter optimization: Big picture
Grid search
Break
Randomized search
Optimization bias (summary)
iClicker
Imports, Announcements, and LO#
Imports#
import os
import sys
sys.path.append("code/.")
import matplotlib.pyplot as plt
import mglearn
import numpy as np
import pandas as pd
from plotting_functions import *
from sklearn.dummy import DummyClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score, cross_validate, train_test_split
from sklearn.pipeline import Pipeline, make_pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from utils import *
%matplotlib inline
pd.set_option("display.max_colwidth", 200)
from sklearn import set_config
set_config(display="diagram")
Announcements#
HW3 was due last night.
HW4 has been released. (Due next week Tuesday, Oct 10th at 11:59 p.m.)
Learning outcomes#
From this lecture, you will be able to
explain the need for hyperparameter optimization
carry out hyperparameter optimization using
sklearn’sGridSearchCVandRandomizedSearchCVexplain different hyperparameters of
GridSearchCVexplain the importance of selecting a good range for the values.
explain optimization bias
identify and reason when to trust and not trust reported accuracies
Hyperparameter optimization motivation#
Motivation#
Remember that the fundamental goal of supervised machine learning is to generalize beyond what we see in the training examples.
We have been using data splitting and cross-validation to provide a framework to approximate generalization error.
With this framework, we can improve the model’s generalization performance by tuning model hyperparameters using cross-validation on the training set.
Hyperparameters: the problem#
In order to improve the generalization performance, finding the best values for the important hyperparameters of a model is necessary for almost all models and datasets.
Picking good hyperparameters is important because if we don’t do it, we might end up with an underfit or overfit model.
Some ways to pick hyperparameters:#
Manual or expert knowledge or heuristics based optimization
Data-driven or automated optimization
Manual hyperparameter optimization#
Advantage: we may have some intuition about what might work.
E.g. if I’m massively overfitting, try decreasing
max_depthorC.
Disadvantages
it takes a lot of work
not reproducible
in very complicated cases, our intuition might be worse than a data-driven approach
Automated hyperparameter optimization#
Formulate the hyperparamter optimization as a one big search problem.
Often we have many hyperparameters of different types: Categorical, integer, and continuous.
Often, the search space is quite big and systematic search for optimal values is infeasible.
In homework assignments, we have been carrying out hyperparameter search by exhaustively trying different possible combinations of the hyperparameters of interest.
mglearn.plots.plot_grid_search_overview()
Let’s look at an example of tuning max_depth of the DecisionTreeClassifier on the Spotify dataset.
spotify_df = pd.read_csv("data/spotify.csv", index_col=0)
X_spotify = spotify_df.drop(columns=["target", "artist"])
y_spotify = spotify_df["target"]
X_spotify.head()
| acousticness | danceability | duration_ms | energy | instrumentalness | key | liveness | loudness | mode | speechiness | tempo | time_signature | valence | song_title | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0102 | 0.833 | 204600 | 0.434 | 0.021900 | 2 | 0.1650 | -8.795 | 1 | 0.4310 | 150.062 | 4.0 | 0.286 | Mask Off |
| 1 | 0.1990 | 0.743 | 326933 | 0.359 | 0.006110 | 1 | 0.1370 | -10.401 | 1 | 0.0794 | 160.083 | 4.0 | 0.588 | Redbone |
| 2 | 0.0344 | 0.838 | 185707 | 0.412 | 0.000234 | 2 | 0.1590 | -7.148 | 1 | 0.2890 | 75.044 | 4.0 | 0.173 | Xanny Family |
| 3 | 0.6040 | 0.494 | 199413 | 0.338 | 0.510000 | 5 | 0.0922 | -15.236 | 1 | 0.0261 | 86.468 | 4.0 | 0.230 | Master Of None |
| 4 | 0.1800 | 0.678 | 392893 | 0.561 | 0.512000 | 5 | 0.4390 | -11.648 | 0 | 0.0694 | 174.004 | 4.0 | 0.904 | Parallel Lines |
X_train, X_test, y_train, y_test = train_test_split(
X_spotify, y_spotify, test_size=0.2, random_state=123
)
numeric_feats = ['acousticness', 'danceability', 'energy',
'instrumentalness', 'liveness', 'loudness',
'speechiness', 'tempo', 'valence']
categorical_feats = ['time_signature', 'key']
passthrough_feats = ['mode']
text_feat = "song_title"
from sklearn.compose import make_column_transformer
from sklearn.feature_extraction.text import CountVectorizer
preprocessor = make_column_transformer(
(StandardScaler(), numeric_feats),
(OneHotEncoder(handle_unknown = "ignore"), categorical_feats),
("passthrough", passthrough_feats),
(CountVectorizer(max_features=100, stop_words="english"), text_feat)
)
svc_pipe = make_pipeline(preprocessor, SVC)
best_score = 0
param_grid = {"max_depth": np.arange(1, 20, 2)}
results_dict = {"max_depth": [], "mean_cv_score": []}
for depth in param_grid[
"max_depth"
]: # for each combination of parameters, train an SVC
dt_pipe = make_pipeline(preprocessor, DecisionTreeClassifier(max_depth=depth))
scores = cross_val_score(dt_pipe, X_train, y_train) # perform cross-validation
mean_score = np.mean(scores) # compute mean cross-validation accuracy
if (
mean_score > best_score
): # if we got a better score, store the score and parameters
best_score = mean_score
best_params = {"max_depth": depth}
results_dict["max_depth"].append(depth)
results_dict["mean_cv_score"].append(mean_score)
best_params
{'max_depth': 5}
best_score
0.7290771686248869
Let’s try SVM RBF and tuning C and gamma on the same dataset.
pipe_svm = make_pipeline(preprocessor, SVC()) # We need scaling for SVM RBF
pipe_svm.fit(X_train, y_train)
Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability', 'energy',
'instrumentalness',
'liveness', 'loudness',
'speechiness', 'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough',
['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])),
('svc', SVC())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability', 'energy',
'instrumentalness',
'liveness', 'loudness',
'speechiness', 'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough',
['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])),
('svc', SVC())])ColumnTransformer(transformers=[('standardscaler', StandardScaler(),
['acousticness', 'danceability', 'energy',
'instrumentalness', 'liveness', 'loudness',
'speechiness', 'tempo', 'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough', ['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])['acousticness', 'danceability', 'energy', 'instrumentalness', 'liveness', 'loudness', 'speechiness', 'tempo', 'valence']
StandardScaler()
['time_signature', 'key']
OneHotEncoder(handle_unknown='ignore')
['mode']
passthrough
song_title
CountVectorizer(max_features=100, stop_words='english')
SVC()
Let’s try cross-validation with default hyperparameters of SVC.
scores = cross_validate(pipe_svm, X_train, y_train, return_train_score=True)
pd.DataFrame(scores).mean()
fit_time 0.044858
score_time 0.011283
test_score 0.734011
train_score 0.828891
dtype: float64
Now let’s try exhaustive hyperparameter search using for loops.
This is what we have been doing for this:
for gamma in [0.01, 1, 10, 100]: # for some values of gamma
for C in [0.01, 1, 10, 100]: # for some values of C
for fold in folds:
fit in training portion with the given C
score on validation portion
compute average score
pick hyperparameter values which yield with best average score
best_score = 0
param_grid = {
"C": [0.001, 0.01, 0.1, 1, 10, 100],
"gamma": [0.001, 0.01, 0.1, 1, 10, 100],
}
results_dict = {"C": [], "gamma": [], "mean_cv_score": []}
for gamma in param_grid["gamma"]:
for C in param_grid["C"]: # for each combination of parameters, train an SVC
pipe_svm = make_pipeline(preprocessor, SVC(gamma=gamma, C=C))
scores = cross_val_score(pipe_svm, X_train, y_train) # perform cross-validation
mean_score = np.mean(scores) # compute mean cross-validation accuracy
if (
mean_score > best_score
): # if we got a better score, store the score and parameters
best_score = mean_score
best_parameters = {"C": C, "gamma": gamma}
results_dict["C"].append(C)
results_dict["gamma"].append(gamma)
results_dict["mean_cv_score"].append(mean_score)
best_parameters
{'C': 1, 'gamma': 0.1}
best_score
0.7352614272253524
df = pd.DataFrame(results_dict)
df.sort_values(by="mean_cv_score", ascending=False).head(10)
| C | gamma | mean_cv_score | |
|---|---|---|---|
| 15 | 1.0 | 0.100 | 0.735261 |
| 16 | 10.0 | 0.100 | 0.722249 |
| 11 | 100.0 | 0.010 | 0.716657 |
| 10 | 10.0 | 0.010 | 0.716655 |
| 5 | 100.0 | 0.001 | 0.705511 |
| 14 | 0.1 | 0.100 | 0.701173 |
| 9 | 1.0 | 0.010 | 0.691877 |
| 17 | 100.0 | 0.100 | 0.677601 |
| 4 | 10.0 | 0.001 | 0.673277 |
| 8 | 0.1 | 0.010 | 0.652828 |
scores = np.array(df.mean_cv_score).reshape(6, 6)
my_heatmap(
scores,
xlabel="C",
xticklabels=param_grid["C"],
ylabel="gamma",
yticklabels=param_grid["gamma"],
cmap="viridis",
fmt="%0.2f"
);
# plot the mean cross-validation scores
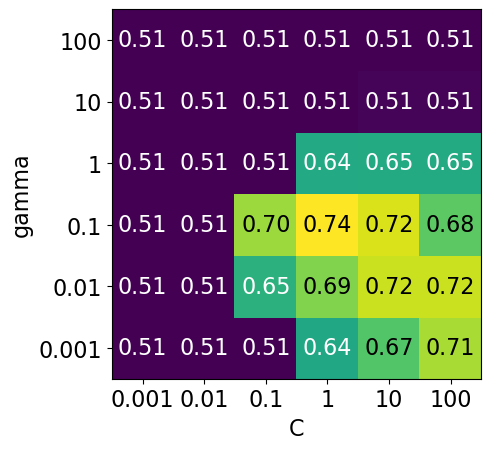
We have 6 possible values for
Cand 6 possible values forgamma.In 5-fold cross-validation, for each combination of parameter values, five accuracies are computed.
So to evaluate the accuracy of the SVM using 6 values of
Cand 6 values ofgammausing five-fold cross-validation, we need to train 36 * 5 = 180 models!
np.prod(list(map(len, param_grid.values())))
36
Once we have optimized hyperparameters, we retrain a model on the full training set with these optimized hyperparameters.
pipe_svm = make_pipeline(preprocessor, SVC(**best_parameters))
pipe_svm.fit(
X_train, y_train
) # Retrain a model with optimized hyperparameters on the combined training and validation set
Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability', 'energy',
'instrumentalness',
'liveness', 'loudness',
'speechiness', 'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough',
['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])),
('svc', SVC(C=1, gamma=0.1))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability', 'energy',
'instrumentalness',
'liveness', 'loudness',
'speechiness', 'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough',
['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])),
('svc', SVC(C=1, gamma=0.1))])ColumnTransformer(transformers=[('standardscaler', StandardScaler(),
['acousticness', 'danceability', 'energy',
'instrumentalness', 'liveness', 'loudness',
'speechiness', 'tempo', 'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough', ['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])['acousticness', 'danceability', 'energy', 'instrumentalness', 'liveness', 'loudness', 'speechiness', 'tempo', 'valence']
StandardScaler()
['time_signature', 'key']
OneHotEncoder(handle_unknown='ignore')
['mode']
passthrough
song_title
CountVectorizer(max_features=100, stop_words='english')
SVC(C=1, gamma=0.1)
Note
In Python, the double asterisk (**) followed by a variable name is used to pass a variable number of keyword arguments to a function. This allows to pass a dictionary of named arguments to a function, where keys of the dictionary become the argument names and values vecome the corresponding argument values.
And finally evaluate the performance of this model on the test set.
pipe_svm.score(X_test, y_test) # Final evaluation on the test data
0.75
This process is so common that there are some standard methods in scikit-learn where we can carry out all of this in a more compact way.
mglearn.plots.plot_grid_search_overview()
In this lecture we are going to talk about two such most commonly used automated optimizations methods from scikit-learn.
Exhaustive grid search:
sklearn.model_selection.GridSearchCVRandomized search:
sklearn.model_selection.RandomizedSearchCV
The “CV” stands for cross-validation; these methods have built-in cross-validation.
Exhaustive grid search: sklearn.model_selection.GridSearchCV#
For
GridSearchCVwe needan instantiated model or a pipeline
a parameter grid: A user specifies a set of values for each hyperparameter.
other optional arguments
The method considers product of the sets and evaluates each combination one by one.
from sklearn.model_selection import GridSearchCV
pipe_svm = make_pipeline(preprocessor, SVC())
param_grid = {
"columntransformer__countvectorizer__max_features": [100, 200, 400, 800, 1000, 2000],
"svc__gamma": [0.001, 0.01, 0.1, 1.0, 10, 100],
"svc__C": [0.001, 0.01, 0.1, 1.0, 10, 100],
}
# Create a grid search object
gs = GridSearchCV(pipe_svm,
param_grid = param_grid,
n_jobs=-1,
return_train_score=True
)
The GridSearchCV object above behaves like a classifier. We can call fit, predict or score on it.
# Carry out the search
gs.fit(X_train, y_train)
GridSearchCV(estimator=Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability',
'energy',
'instrumentalness',
'liveness',
'loudness',
'speechiness',
'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature',
'key']),
('passthrough',
'passthrough',
['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])),
('svc', SVC())]),
n_jobs=-1,
param_grid={'columntransformer__countvectorizer__max_features': [100,
200,
400,
800,
1000,
2000],
'svc__C': [0.001, 0.01, 0.1, 1.0, 10, 100],
'svc__gamma': [0.001, 0.01, 0.1, 1.0, 10, 100]},
return_train_score=True)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
GridSearchCV(estimator=Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability',
'energy',
'instrumentalness',
'liveness',
'loudness',
'speechiness',
'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature',
'key']),
('passthrough',
'passthrough',
['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])),
('svc', SVC())]),
n_jobs=-1,
param_grid={'columntransformer__countvectorizer__max_features': [100,
200,
400,
800,
1000,
2000],
'svc__C': [0.001, 0.01, 0.1, 1.0, 10, 100],
'svc__gamma': [0.001, 0.01, 0.1, 1.0, 10, 100]},
return_train_score=True)Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability', 'energy',
'instrumentalness',
'liveness', 'loudness',
'speechiness', 'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough',
['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])),
('svc', SVC())])ColumnTransformer(transformers=[('standardscaler', StandardScaler(),
['acousticness', 'danceability', 'energy',
'instrumentalness', 'liveness', 'loudness',
'speechiness', 'tempo', 'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough', ['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])['acousticness', 'danceability', 'energy', 'instrumentalness', 'liveness', 'loudness', 'speechiness', 'tempo', 'valence']
StandardScaler()
['time_signature', 'key']
OneHotEncoder(handle_unknown='ignore')
['mode']
passthrough
song_title
CountVectorizer(max_features=100, stop_words='english')
SVC()
Fitting the GridSearchCV object
Searches for the best hyperparameter values
You can access the best score and the best hyperparameters using
best_score_andbest_params_attributes, respectively.
# Get the best score
gs.best_score_
0.7395977155164125
# Get the best hyperparameter values
gs.best_params_
{'columntransformer__countvectorizer__max_features': 1000,
'svc__C': 1.0,
'svc__gamma': 0.1}
It is often helpful to visualize results of all cross-validation experiments.
You can access this information using
cv_results_attribute of a fittedGridSearchCVobject.
results = pd.DataFrame(gs.cv_results_)
results.T
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 206 | 207 | 208 | 209 | 210 | 211 | 212 | 213 | 214 | 215 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean_fit_time | 0.084799 | 0.083365 | 0.081087 | 0.08117 | 0.076375 | 0.087916 | 0.079953 | 0.080694 | 0.078242 | 0.078036 | ... | 0.134974 | 0.112302 | 0.131705 | 0.111314 | 0.094516 | 0.165202 | 0.127544 | 0.121308 | 0.1134 | 0.11573 |
| std_fit_time | 0.007823 | 0.009193 | 0.009527 | 0.006456 | 0.005406 | 0.016433 | 0.009664 | 0.004703 | 0.002725 | 0.00311 | ... | 0.00403 | 0.007545 | 0.027318 | 0.006043 | 0.006947 | 0.008738 | 0.011222 | 0.015188 | 0.020808 | 0.014656 |
| mean_score_time | 0.020058 | 0.027582 | 0.021574 | 0.022042 | 0.019047 | 0.021058 | 0.020972 | 0.020351 | 0.02134 | 0.02366 | ... | 0.025311 | 0.02239 | 0.023252 | 0.024485 | 0.021746 | 0.022081 | 0.023824 | 0.025381 | 0.025123 | 0.022704 |
| std_score_time | 0.002327 | 0.008256 | 0.006856 | 0.002381 | 0.00226 | 0.003775 | 0.000429 | 0.000397 | 0.001015 | 0.003933 | ... | 0.007308 | 0.004024 | 0.002661 | 0.002022 | 0.001018 | 0.003054 | 0.005262 | 0.006015 | 0.008522 | 0.003892 |
| param_columntransformer__countvectorizer__max_features | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | ... | 2000 | 2000 | 2000 | 2000 | 2000 | 2000 | 2000 | 2000 | 2000 | 2000 |
| param_svc__C | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.01 | 0.01 | 0.01 | 0.01 | ... | 10 | 10 | 10 | 10 | 100 | 100 | 100 | 100 | 100 | 100 |
| param_svc__gamma | 0.001 | 0.01 | 0.1 | 1.0 | 10 | 100 | 0.001 | 0.01 | 0.1 | 1.0 | ... | 0.1 | 1.0 | 10 | 100 | 0.001 | 0.01 | 0.1 | 1.0 | 10 | 100 |
| params | {'columntransformer__countvectorizer__max_features': 100, 'svc__C': 0.001, 'svc__gamma': 0.001} | {'columntransformer__countvectorizer__max_features': 100, 'svc__C': 0.001, 'svc__gamma': 0.01} | {'columntransformer__countvectorizer__max_features': 100, 'svc__C': 0.001, 'svc__gamma': 0.1} | {'columntransformer__countvectorizer__max_features': 100, 'svc__C': 0.001, 'svc__gamma': 1.0} | {'columntransformer__countvectorizer__max_features': 100, 'svc__C': 0.001, 'svc__gamma': 10} | {'columntransformer__countvectorizer__max_features': 100, 'svc__C': 0.001, 'svc__gamma': 100} | {'columntransformer__countvectorizer__max_features': 100, 'svc__C': 0.01, 'svc__gamma': 0.001} | {'columntransformer__countvectorizer__max_features': 100, 'svc__C': 0.01, 'svc__gamma': 0.01} | {'columntransformer__countvectorizer__max_features': 100, 'svc__C': 0.01, 'svc__gamma': 0.1} | {'columntransformer__countvectorizer__max_features': 100, 'svc__C': 0.01, 'svc__gamma': 1.0} | ... | {'columntransformer__countvectorizer__max_features': 2000, 'svc__C': 10, 'svc__gamma': 0.1} | {'columntransformer__countvectorizer__max_features': 2000, 'svc__C': 10, 'svc__gamma': 1.0} | {'columntransformer__countvectorizer__max_features': 2000, 'svc__C': 10, 'svc__gamma': 10} | {'columntransformer__countvectorizer__max_features': 2000, 'svc__C': 10, 'svc__gamma': 100} | {'columntransformer__countvectorizer__max_features': 2000, 'svc__C': 100, 'svc__gamma': 0.001} | {'columntransformer__countvectorizer__max_features': 2000, 'svc__C': 100, 'svc__gamma': 0.01} | {'columntransformer__countvectorizer__max_features': 2000, 'svc__C': 100, 'svc__gamma': 0.1} | {'columntransformer__countvectorizer__max_features': 2000, 'svc__C': 100, 'svc__gamma': 1.0} | {'columntransformer__countvectorizer__max_features': 2000, 'svc__C': 100, 'svc__gamma': 10} | {'columntransformer__countvectorizer__max_features': 2000, 'svc__C': 100, 'svc__gamma': 100} |
| split0_test_score | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | ... | 0.733746 | 0.616099 | 0.50774 | 0.504644 | 0.718266 | 0.718266 | 0.724458 | 0.616099 | 0.50774 | 0.504644 |
| split1_test_score | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | ... | 0.77709 | 0.625387 | 0.510836 | 0.510836 | 0.724458 | 0.739938 | 0.764706 | 0.625387 | 0.510836 | 0.510836 |
| split2_test_score | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | ... | 0.690402 | 0.606811 | 0.50774 | 0.50774 | 0.693498 | 0.705882 | 0.687307 | 0.606811 | 0.50774 | 0.50774 |
| split3_test_score | 0.506211 | 0.506211 | 0.506211 | 0.506211 | 0.506211 | 0.506211 | 0.506211 | 0.506211 | 0.506211 | 0.506211 | ... | 0.708075 | 0.618012 | 0.509317 | 0.509317 | 0.68323 | 0.704969 | 0.708075 | 0.618012 | 0.509317 | 0.509317 |
| split4_test_score | 0.509317 | 0.509317 | 0.509317 | 0.509317 | 0.509317 | 0.509317 | 0.509317 | 0.509317 | 0.509317 | 0.509317 | ... | 0.723602 | 0.645963 | 0.509317 | 0.509317 | 0.720497 | 0.717391 | 0.720497 | 0.645963 | 0.509317 | 0.509317 |
| mean_test_score | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | ... | 0.726583 | 0.622454 | 0.50899 | 0.508371 | 0.70799 | 0.717289 | 0.721008 | 0.622454 | 0.50899 | 0.508371 |
| std_test_score | 0.000982 | 0.000982 | 0.000982 | 0.000982 | 0.000982 | 0.000982 | 0.000982 | 0.000982 | 0.000982 | 0.000982 | ... | 0.029198 | 0.013161 | 0.001162 | 0.002105 | 0.01647 | 0.012616 | 0.025396 | 0.013161 | 0.001162 | 0.002105 |
| rank_test_score | 121 | 121 | 121 | 121 | 121 | 121 | 121 | 121 | 121 | 121 | ... | 9 | 81 | 91 | 97 | 28 | 22 | 18 | 81 | 91 | 97 |
| split0_train_score | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | ... | 1.0 | 1.0 | 1.0 | 1.0 | 0.828682 | 0.989147 | 1.0 | 1.0 | 1.0 | 1.0 |
| split1_train_score | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | ... | 0.999225 | 1.0 | 1.0 | 1.0 | 0.834109 | 0.989922 | 1.0 | 1.0 | 1.0 | 1.0 |
| split2_train_score | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | ... | 0.99845 | 0.999225 | 0.999225 | 0.999225 | 0.827907 | 0.987597 | 0.999225 | 0.999225 | 0.999225 | 0.999225 |
| split3_train_score | 0.508133 | 0.508133 | 0.508133 | 0.508133 | 0.508133 | 0.508133 | 0.508133 | 0.508133 | 0.508133 | 0.508133 | ... | 0.998451 | 0.999225 | 0.999225 | 0.999225 | 0.841208 | 0.989156 | 0.999225 | 0.999225 | 0.999225 | 0.999225 |
| split4_train_score | 0.507359 | 0.507359 | 0.507359 | 0.507359 | 0.507359 | 0.507359 | 0.507359 | 0.507359 | 0.507359 | 0.507359 | ... | 0.999225 | 0.999225 | 0.999225 | 0.999225 | 0.82804 | 0.988381 | 0.999225 | 0.999225 | 0.999225 | 0.999225 |
| mean_train_score | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | ... | 0.99907 | 0.999535 | 0.999535 | 0.999535 | 0.831989 | 0.988841 | 0.999535 | 0.999535 | 0.999535 | 0.999535 |
| std_train_score | 0.000245 | 0.000245 | 0.000245 | 0.000245 | 0.000245 | 0.000245 | 0.000245 | 0.000245 | 0.000245 | 0.000245 | ... | 0.00058 | 0.00038 | 0.00038 | 0.00038 | 0.005151 | 0.00079 | 0.00038 | 0.00038 | 0.00038 | 0.00038 |
23 rows × 216 columns
results = (
pd.DataFrame(gs.cv_results_).set_index("rank_test_score").sort_index()
)
display(results.T)
| rank_test_score | 1 | 2 | 3 | 4 | 5 | 5 | 7 | 8 | 9 | 10 | ... | 121 | 121 | 121 | 121 | 121 | 121 | 121 | 121 | 121 | 121 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean_fit_time | 0.084821 | 0.092701 | 0.080693 | 0.08178 | 0.072704 | 0.071951 | 0.119087 | 0.122358 | 0.134974 | 0.120067 | ... | 0.092312 | 0.095218 | 0.096805 | 0.089774 | 0.087583 | 0.081031 | 0.093778 | 0.092827 | 0.090954 | 0.084799 |
| std_fit_time | 0.012817 | 0.004912 | 0.003299 | 0.00672 | 0.003707 | 0.004959 | 0.002752 | 0.021941 | 0.00403 | 0.007395 | ... | 0.009119 | 0.008261 | 0.019061 | 0.008197 | 0.003097 | 0.005002 | 0.013358 | 0.014488 | 0.006715 | 0.007823 |
| mean_score_time | 0.022616 | 0.019873 | 0.016402 | 0.02012 | 0.017569 | 0.0176 | 0.019607 | 0.018281 | 0.025311 | 0.018196 | ... | 0.024594 | 0.025063 | 0.019473 | 0.022577 | 0.023586 | 0.023957 | 0.022811 | 0.023648 | 0.02207 | 0.020058 |
| std_score_time | 0.004053 | 0.002547 | 0.001912 | 0.000593 | 0.002468 | 0.000793 | 0.000783 | 0.002834 | 0.007308 | 0.00294 | ... | 0.001628 | 0.005281 | 0.002502 | 0.000883 | 0.001097 | 0.00834 | 0.000922 | 0.003478 | 0.00097 | 0.002327 |
| param_columntransformer__countvectorizer__max_features | 1000 | 2000 | 400 | 800 | 200 | 100 | 800 | 1000 | 2000 | 400 | ... | 1000 | 1000 | 1000 | 400 | 400 | 400 | 400 | 400 | 1000 | 100 |
| param_svc__C | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 10 | 10 | 10 | 10 | ... | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
| param_svc__gamma | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | ... | 0.1 | 0.01 | 0.001 | 0.001 | 0.01 | 0.1 | 1.0 | 10 | 100 | 0.001 |
| params | {'columntransformer__countvectorizer__max_features': 1000, 'svc__C': 1.0, 'svc__gamma': 0.1} | {'columntransformer__countvectorizer__max_features': 2000, 'svc__C': 1.0, 'svc__gamma': 0.1} | {'columntransformer__countvectorizer__max_features': 400, 'svc__C': 1.0, 'svc__gamma': 0.1} | {'columntransformer__countvectorizer__max_features': 800, 'svc__C': 1.0, 'svc__gamma': 0.1} | {'columntransformer__countvectorizer__max_features': 200, 'svc__C': 1.0, 'svc__gamma': 0.1} | {'columntransformer__countvectorizer__max_features': 100, 'svc__C': 1.0, 'svc__gamma': 0.1} | {'columntransformer__countvectorizer__max_features': 800, 'svc__C': 10, 'svc__gamma': 0.1} | {'columntransformer__countvectorizer__max_features': 1000, 'svc__C': 10, 'svc__gamma': 0.1} | {'columntransformer__countvectorizer__max_features': 2000, 'svc__C': 10, 'svc__gamma': 0.1} | {'columntransformer__countvectorizer__max_features': 400, 'svc__C': 10, 'svc__gamma': 0.1} | ... | {'columntransformer__countvectorizer__max_features': 1000, 'svc__C': 0.001, 'svc__gamma': 0.1} | {'columntransformer__countvectorizer__max_features': 1000, 'svc__C': 0.001, 'svc__gamma': 0.01} | {'columntransformer__countvectorizer__max_features': 1000, 'svc__C': 0.001, 'svc__gamma': 0.001} | {'columntransformer__countvectorizer__max_features': 400, 'svc__C': 0.001, 'svc__gamma': 0.001} | {'columntransformer__countvectorizer__max_features': 400, 'svc__C': 0.001, 'svc__gamma': 0.01} | {'columntransformer__countvectorizer__max_features': 400, 'svc__C': 0.001, 'svc__gamma': 0.1} | {'columntransformer__countvectorizer__max_features': 400, 'svc__C': 0.001, 'svc__gamma': 1.0} | {'columntransformer__countvectorizer__max_features': 400, 'svc__C': 0.001, 'svc__gamma': 10} | {'columntransformer__countvectorizer__max_features': 1000, 'svc__C': 0.001, 'svc__gamma': 100} | {'columntransformer__countvectorizer__max_features': 100, 'svc__C': 0.001, 'svc__gamma': 0.001} |
| split0_test_score | 0.764706 | 0.767802 | 0.764706 | 0.76161 | 0.758514 | 0.76161 | 0.727554 | 0.718266 | 0.733746 | 0.739938 | ... | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 |
| split1_test_score | 0.767802 | 0.770898 | 0.764706 | 0.76161 | 0.758514 | 0.755418 | 0.77709 | 0.783282 | 0.77709 | 0.783282 | ... | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 |
| split2_test_score | 0.71517 | 0.708978 | 0.708978 | 0.712074 | 0.712074 | 0.712074 | 0.690402 | 0.708978 | 0.690402 | 0.693498 | ... | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 | 0.50774 |
| split3_test_score | 0.717391 | 0.717391 | 0.714286 | 0.720497 | 0.717391 | 0.714286 | 0.729814 | 0.717391 | 0.708075 | 0.714286 | ... | 0.506211 | 0.506211 | 0.506211 | 0.506211 | 0.506211 | 0.506211 | 0.506211 | 0.506211 | 0.506211 | 0.506211 |
| split4_test_score | 0.732919 | 0.729814 | 0.729814 | 0.723602 | 0.729814 | 0.732919 | 0.714286 | 0.708075 | 0.723602 | 0.701863 | ... | 0.509317 | 0.509317 | 0.509317 | 0.509317 | 0.509317 | 0.509317 | 0.509317 | 0.509317 | 0.509317 | 0.509317 |
| mean_test_score | 0.739598 | 0.738977 | 0.736498 | 0.735879 | 0.735261 | 0.735261 | 0.727829 | 0.727198 | 0.726583 | 0.726573 | ... | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 |
| std_test_score | 0.022629 | 0.025689 | 0.024028 | 0.021345 | 0.019839 | 0.020414 | 0.028337 | 0.028351 | 0.029198 | 0.032404 | ... | 0.000982 | 0.000982 | 0.000982 | 0.000982 | 0.000982 | 0.000982 | 0.000982 | 0.000982 | 0.000982 | 0.000982 |
| split0_train_score | 0.889147 | 0.903101 | 0.881395 | 0.886047 | 0.872093 | 0.856589 | 0.993023 | 0.996899 | 1.0 | 0.986047 | ... | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 |
| split1_train_score | 0.877519 | 0.895349 | 0.858915 | 0.873643 | 0.847287 | 0.83876 | 0.993023 | 0.994574 | 0.999225 | 0.987597 | ... | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 |
| split2_train_score | 0.888372 | 0.897674 | 0.87907 | 0.887597 | 0.85969 | 0.849612 | 0.994574 | 0.994574 | 0.99845 | 0.989922 | ... | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 | 0.507752 |
| split3_train_score | 0.884586 | 0.902401 | 0.869094 | 0.879938 | 0.859799 | 0.852053 | 0.989156 | 0.992254 | 0.998451 | 0.982184 | ... | 0.508133 | 0.508133 | 0.508133 | 0.508133 | 0.508133 | 0.508133 | 0.508133 | 0.508133 | 0.508133 | 0.508133 |
| split4_train_score | 0.876065 | 0.891557 | 0.861348 | 0.874516 | 0.850503 | 0.841983 | 0.992254 | 0.993029 | 0.999225 | 0.985283 | ... | 0.507359 | 0.507359 | 0.507359 | 0.507359 | 0.507359 | 0.507359 | 0.507359 | 0.507359 | 0.507359 | 0.507359 |
| mean_train_score | 0.883138 | 0.898016 | 0.869964 | 0.880348 | 0.857874 | 0.847799 | 0.992406 | 0.994266 | 0.99907 | 0.986207 | ... | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 |
| std_train_score | 0.005426 | 0.004337 | 0.009063 | 0.00573 | 0.008667 | 0.006545 | 0.001792 | 0.001594 | 0.00058 | 0.002561 | ... | 0.000245 | 0.000245 | 0.000245 | 0.000245 | 0.000245 | 0.000245 | 0.000245 | 0.000245 | 0.000245 | 0.000245 |
22 rows × 216 columns
Let’s only look at the most relevant rows.
pd.DataFrame(gs.cv_results_)[
[
"mean_test_score",
"param_columntransformer__countvectorizer__max_features",
"param_svc__gamma",
"param_svc__C",
"mean_fit_time",
"rank_test_score",
]
].set_index("rank_test_score").sort_index().T
| rank_test_score | 1 | 2 | 3 | 4 | 5 | 5 | 7 | 8 | 9 | 10 | ... | 121 | 121 | 121 | 121 | 121 | 121 | 121 | 121 | 121 | 121 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean_test_score | 0.739598 | 0.738977 | 0.736498 | 0.735879 | 0.735261 | 0.735261 | 0.727829 | 0.727198 | 0.726583 | 0.726573 | ... | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 | 0.50775 |
| param_columntransformer__countvectorizer__max_features | 1000 | 2000 | 400 | 800 | 200 | 100 | 800 | 1000 | 2000 | 400 | ... | 1000 | 1000 | 1000 | 400 | 400 | 400 | 400 | 400 | 1000 | 100 |
| param_svc__gamma | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | ... | 0.1 | 0.01 | 0.001 | 0.001 | 0.01 | 0.1 | 1.0 | 10 | 100 | 0.001 |
| param_svc__C | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 10 | 10 | 10 | 10 | ... | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
| mean_fit_time | 0.084821 | 0.092701 | 0.080693 | 0.08178 | 0.072704 | 0.071951 | 0.119087 | 0.122358 | 0.134974 | 0.120067 | ... | 0.092312 | 0.095218 | 0.096805 | 0.089774 | 0.087583 | 0.081031 | 0.093778 | 0.092827 | 0.090954 | 0.084799 |
5 rows × 216 columns
Other than searching for best hyperparameter values,
GridSearchCValso fits a new model on the whole training set with the parameters that yielded the best results.So we can conveniently call
scoreon the test set with a fittedGridSearchCVobject.
# Get the test scores
gs.score(X_test, y_test)
0.7574257425742574
Why are best_score_ and the score above different?
n_jobs=-1#
Note the
n_jobs=-1above.Hyperparameter optimization can be done in parallel for each of the configurations.
This is very useful when scaling up to large numbers of machines in the cloud.
When you set
n_jobs=-1, it means that you want to use all available CPU cores for the task.
The __ syntax#
Above: we have a nesting of transformers.
We can access the parameters of the “inner” objects by using __ to go “deeper”:
svc__gamma: thegammaof thesvcof the pipelinesvc__C: theCof thesvcof the pipelinecolumntransformer__countvectorizer__max_features: themax_featureshyperparameter ofCountVectorizerin the column transformerpreprocessor.
pipe_svm
Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability', 'energy',
'instrumentalness',
'liveness', 'loudness',
'speechiness', 'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough',
['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])),
('svc', SVC())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability', 'energy',
'instrumentalness',
'liveness', 'loudness',
'speechiness', 'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough',
['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])),
('svc', SVC())])ColumnTransformer(transformers=[('standardscaler', StandardScaler(),
['acousticness', 'danceability', 'energy',
'instrumentalness', 'liveness', 'loudness',
'speechiness', 'tempo', 'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough', ['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])['acousticness', 'danceability', 'energy', 'instrumentalness', 'liveness', 'loudness', 'speechiness', 'tempo', 'valence']
StandardScaler()
['time_signature', 'key']
OneHotEncoder(handle_unknown='ignore')
['mode']
passthrough
song_title
CountVectorizer(max_features=100, stop_words='english')
SVC()
Range of C#
Note the exponential range for
C. This is quite common. Using this exponential range allows you to explore a wide range of values efficiently.There is no point trying \(C=\{1,2,3\ldots,100\}\) because \(C=1,2,3\) are too similar to each other.
Often we’re trying to find an order of magnitude, e.g. \(C=\{0.01,0.1,1,10,100\}\).
We can also write that as \(C=\{10^{-2},10^{-1},10^0,10^1,10^2\}\).
Or, in other words, \(C\) values to try are \(10^n\) for \(n=-2,-1,0,1,2\) which is basically what we have above.
Visualizing the parameter grid as a heatmap#
def display_heatmap(param_grid, pipe, X_train, y_train):
grid_search = GridSearchCV(
pipe, param_grid, cv=5, n_jobs=-1, return_train_score=True
)
grid_search.fit(X_train, y_train)
results = pd.DataFrame(grid_search.cv_results_)
scores = np.array(results.mean_test_score).reshape(6, 6)
# plot the mean cross-validation scores
my_heatmap(
scores,
xlabel="gamma",
xticklabels=param_grid["svc__gamma"],
ylabel="C",
yticklabels=param_grid["svc__C"],
cmap="viridis",
);
Note that the range we pick for the parameters play an important role in hyperparameter optimization.
For example, consider the following grid and the corresponding results.
param_grid1 = {
"svc__gamma": 10.0**np.arange(-3, 3, 1),
"svc__C": 10.0**np.arange(-3, 3, 1)
}
display_heatmap(param_grid1, pipe_svm, X_train, y_train)
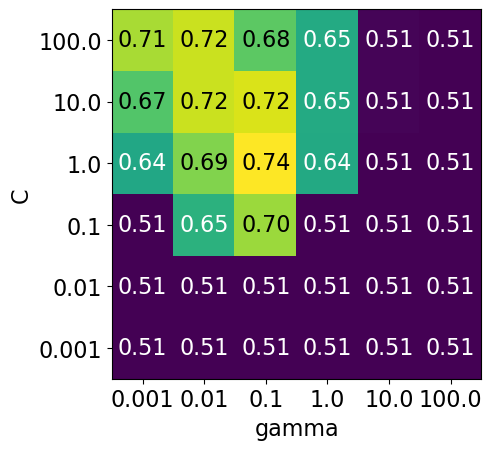
Each point in the heat map corresponds to one run of cross-validation, with a particular setting
Colour encodes cross-validation accuracy.
Lighter colour means high accuracy
Darker colour means low accuracy
SVC is quite sensitive to hyperparameter settings.
Adjusting hyperparameters can change the accuracy from 0.51 to 0.74!
Bad range for hyperparameters#
np.logspace(1, 2, 6)
array([ 10. , 15.84893192, 25.11886432, 39.81071706,
63.09573445, 100. ])
np.linspace(1, 2, 6)
array([1. , 1.2, 1.4, 1.6, 1.8, 2. ])
param_grid2 = {"svc__gamma": np.round(np.logspace(1, 2, 6), 1), "svc__C": np.linspace(1, 2, 6)}
display_heatmap(param_grid2, pipe_svm, X_train, y_train)
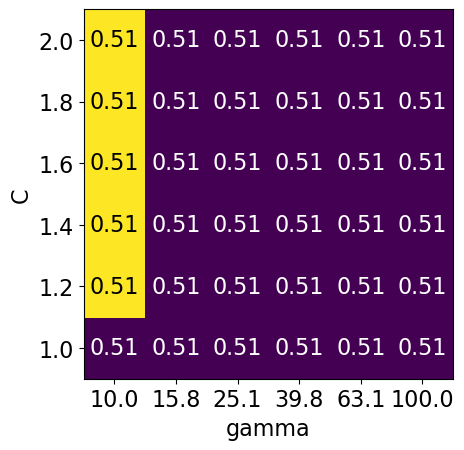
Different range for hyperparameters yields better results!#
np.logspace(-3, 2, 6)
array([1.e-03, 1.e-02, 1.e-01, 1.e+00, 1.e+01, 1.e+02])
np.linspace(1, 2, 6)
array([1. , 1.2, 1.4, 1.6, 1.8, 2. ])
param_grid3 = {"svc__gamma": np.logspace(-3, 2, 6), "svc__C": np.linspace(1, 2, 6)}
display_heatmap(param_grid3, pipe_svm, X_train, y_train)
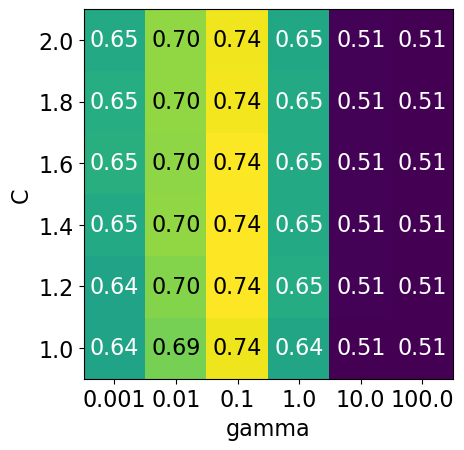
It seems like we are getting even better cross-validation results with C = 2.0 and gamma = 0.1
How about exploring different values of C close to 2.0?
param_grid4 = {"svc__gamma": np.logspace(-3, 2, 6), "svc__C": np.linspace(2, 3, 6)}
display_heatmap(param_grid4, pipe_svm, X_train, y_train)
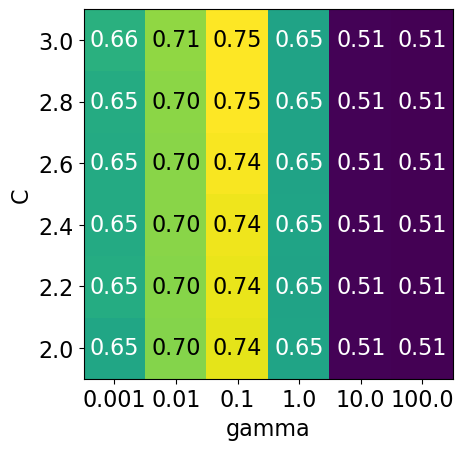
That’s good! We are finding some more options for C where the accuracy is 0.75.
The tricky part is we do not know in advance what range of hyperparameters might work the best for the given problem, model, and the dataset.
Note
GridSearchCV allows the param_grid to be a list of dictionaries. Sometimes some hyperparameters are applicable only for certain models.
For example, in the context of SVC, C and gamma are applicable when the kernel is rbf whereas only C is applicable for kernel="linear".
Problems with exhaustive grid search#
Required number of models to evaluate grows exponentially with the dimensionally of the configuration space.
Example: Suppose you have
5 hyperparameters
10 different values for each hyperparameter
You’ll be evaluating \(10^5=100,000\) models! That is you’ll be calling
cross_validate100,000 times!
Exhaustive search may become infeasible fairly quickly.
Other options?
Randomized hyperparameter search#
Randomized hyperparameter optimization
Samples configurations at random until certain budget (e.g., time) is exhausted
from sklearn.model_selection import RandomizedSearchCV
param_grid = {
"columntransformer__countvectorizer__max_features": [100, 200, 400, 800, 1000, 2000],
"svc__gamma": [0.001, 0.01, 0.1, 1.0, 10, 100],
"svc__C": np.linspace(2, 3, 6),
}
print("Grid size: %d" % (np.prod(list(map(len, param_grid.values())))))
param_grid
Grid size: 216
{'columntransformer__countvectorizer__max_features': [100,
200,
400,
800,
1000,
2000],
'svc__gamma': [0.001, 0.01, 0.1, 1.0, 10, 100],
'svc__C': array([2. , 2.2, 2.4, 2.6, 2.8, 3. ])}
# Create a random search object
random_search = RandomizedSearchCV(pipe_svm,
param_distributions = param_grid,
n_iter=100,
n_jobs=-1,
return_train_score=True)
# Carry out the search
random_search.fit(X_train, y_train)
RandomizedSearchCV(estimator=Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability',
'energy',
'instrumentalness',
'liveness',
'loudness',
'speechiness',
'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature',
'key']),
('passthrough',
'passthrough',
['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])),
('svc', SVC())]),
n_iter=100, n_jobs=-1,
param_distributions={'columntransformer__countvectorizer__max_features': [100,
200,
400,
800,
1000,
2000],
'svc__C': array([2. , 2.2, 2.4, 2.6, 2.8, 3. ]),
'svc__gamma': [0.001, 0.01, 0.1, 1.0,
10, 100]},
return_train_score=True)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomizedSearchCV(estimator=Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability',
'energy',
'instrumentalness',
'liveness',
'loudness',
'speechiness',
'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature',
'key']),
('passthrough',
'passthrough',
['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])),
('svc', SVC())]),
n_iter=100, n_jobs=-1,
param_distributions={'columntransformer__countvectorizer__max_features': [100,
200,
400,
800,
1000,
2000],
'svc__C': array([2. , 2.2, 2.4, 2.6, 2.8, 3. ]),
'svc__gamma': [0.001, 0.01, 0.1, 1.0,
10, 100]},
return_train_score=True)Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability', 'energy',
'instrumentalness',
'liveness', 'loudness',
'speechiness', 'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough',
['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])),
('svc', SVC())])ColumnTransformer(transformers=[('standardscaler', StandardScaler(),
['acousticness', 'danceability', 'energy',
'instrumentalness', 'liveness', 'loudness',
'speechiness', 'tempo', 'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough', ['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])['acousticness', 'danceability', 'energy', 'instrumentalness', 'liveness', 'loudness', 'speechiness', 'tempo', 'valence']
StandardScaler()
['time_signature', 'key']
OneHotEncoder(handle_unknown='ignore')
['mode']
passthrough
song_title
CountVectorizer(max_features=100, stop_words='english')
SVC()
pd.DataFrame(random_search.cv_results_)[
[
"mean_test_score",
"param_columntransformer__countvectorizer__max_features",
"param_svc__gamma",
"param_svc__C",
"mean_fit_time",
"rank_test_score",
]
].set_index("rank_test_score").sort_index().T
| rank_test_score | 1 | 2 | 3 | 4 | 4 | 6 | 7 | 8 | 8 | 10 | ... | 84 | 84 | 84 | 84 | 84 | 84 | 84 | 84 | 84 | 84 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean_test_score | 0.745178 | 0.744565 | 0.743949 | 0.743323 | 0.743323 | 0.743321 | 0.742703 | 0.742088 | 0.742088 | 0.741463 | ... | 0.508371 | 0.508371 | 0.508371 | 0.508371 | 0.508371 | 0.508371 | 0.508371 | 0.508371 | 0.508371 | 0.508371 |
| param_columntransformer__countvectorizer__max_features | 100 | 400 | 400 | 100 | 200 | 2000 | 2000 | 400 | 2000 | 1000 | ... | 2000 | 1000 | 400 | 800 | 100 | 400 | 200 | 1000 | 1000 | 800 |
| param_svc__gamma | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | ... | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| param_svc__C | 3.0 | 3.0 | 2.8 | 2.6 | 2.6 | 2.0 | 2.4 | 2.6 | 2.6 | 3.0 | ... | 2.8 | 3.0 | 2.4 | 2.4 | 2.2 | 3.0 | 2.8 | 2.6 | 2.2 | 2.2 |
| mean_fit_time | 0.083196 | 0.092198 | 0.091333 | 0.076871 | 0.081577 | 0.107743 | 0.119141 | 0.083906 | 0.116113 | 0.111632 | ... | 0.112661 | 0.108607 | 0.109723 | 0.110193 | 0.103863 | 0.110676 | 0.109469 | 0.113928 | 0.110735 | 0.097529 |
5 rows × 100 columns
n_iter#
Note the
n_iter, we didn’t need this forGridSearchCV.Larger
n_iterwill take longer but it’ll do more searching.Remember you still need to multiply by number of folds!
I have set the
random_statefor reproducibility but you don’t have to do it.
(Optional) Passing probability distributions to random search#
Another thing we can do is give probability distributions to draw from:
from scipy.stats import expon, lognorm, loguniform, randint, uniform, norm, randint
np.random.seed(123)
y = uniform.rvs(0, 5, 10000)
bin = np.arange(-3,8,0.1)
plt.hist(y, bins=bin, edgecolor='blue')
plt.show()
y = norm.rvs(0, 1, 10000)
#creating bin
bin = np.arange(-4,4,0.1)
plt.hist(y, bins=bin, edgecolor='blue')
plt.show()
y = expon.rvs(0, 1, 10000)
#creating bin
bin = np.arange(-1,10,0.1)
plt.hist(y, bins=bin, edgecolor='blue')
plt.show()
pipe_svm
Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability', 'energy',
'instrumentalness',
'liveness', 'loudness',
'speechiness', 'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough',
['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])),
('svc', SVC())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability', 'energy',
'instrumentalness',
'liveness', 'loudness',
'speechiness', 'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough',
['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])),
('svc', SVC())])ColumnTransformer(transformers=[('standardscaler', StandardScaler(),
['acousticness', 'danceability', 'energy',
'instrumentalness', 'liveness', 'loudness',
'speechiness', 'tempo', 'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough', ['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])['acousticness', 'danceability', 'energy', 'instrumentalness', 'liveness', 'loudness', 'speechiness', 'tempo', 'valence']
StandardScaler()
['time_signature', 'key']
OneHotEncoder(handle_unknown='ignore')
['mode']
passthrough
song_title
CountVectorizer(max_features=100, stop_words='english')
SVC()
from scipy.stats import randint
param_dist = {
"columntransformer__countvectorizer__max_features": randint(100, 2000),
"svc__C": uniform(0.1, 1e4), # loguniform(1e-3, 1e3),
"svc__gamma": loguniform(1e-5, 1e3),
}
# Create a random search object
random_search = RandomizedSearchCV(pipe_svm,
param_distributions = param_dist,
n_iter=100,
n_jobs=-1,
return_train_score=True)
# Carry out the search
random_search.fit(X_train, y_train)
RandomizedSearchCV(estimator=Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability',
'energy',
'instrumentalness',
'liveness',
'loudness',
'speechiness',
'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature',
'key']),
('passthrough',
'pass...
n_iter=100, n_jobs=-1,
param_distributions={'columntransformer__countvectorizer__max_features': <scipy.stats._distn_infrastructure.rv_discrete_frozen object at 0x144397fd0>,
'svc__C': <scipy.stats._distn_infrastructure.rv_continuous_frozen object at 0x14465c1f0>,
'svc__gamma': <scipy.stats._distn_infrastructure.rv_continuous_frozen object at 0x1442ca9b0>},
return_train_score=True)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomizedSearchCV(estimator=Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability',
'energy',
'instrumentalness',
'liveness',
'loudness',
'speechiness',
'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature',
'key']),
('passthrough',
'pass...
n_iter=100, n_jobs=-1,
param_distributions={'columntransformer__countvectorizer__max_features': <scipy.stats._distn_infrastructure.rv_discrete_frozen object at 0x144397fd0>,
'svc__C': <scipy.stats._distn_infrastructure.rv_continuous_frozen object at 0x14465c1f0>,
'svc__gamma': <scipy.stats._distn_infrastructure.rv_continuous_frozen object at 0x1442ca9b0>},
return_train_score=True)Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability', 'energy',
'instrumentalness',
'liveness', 'loudness',
'speechiness', 'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough',
['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])),
('svc', SVC())])ColumnTransformer(transformers=[('standardscaler', StandardScaler(),
['acousticness', 'danceability', 'energy',
'instrumentalness', 'liveness', 'loudness',
'speechiness', 'tempo', 'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough', ['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])['acousticness', 'danceability', 'energy', 'instrumentalness', 'liveness', 'loudness', 'speechiness', 'tempo', 'valence']
StandardScaler()
['time_signature', 'key']
OneHotEncoder(handle_unknown='ignore')
['mode']
passthrough
song_title
CountVectorizer(max_features=100, stop_words='english')
SVC()
random_search.best_score_
0.7278214718381631
pd.DataFrame(random_search.cv_results_)[
[
"mean_test_score",
"param_columntransformer__countvectorizer__max_features",
"param_svc__gamma",
"param_svc__C",
"mean_fit_time",
"rank_test_score",
]
].set_index("rank_test_score").sort_index().T
| rank_test_score | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ... | 76 | 76 | 76 | 94 | 94 | 94 | 94 | 94 | 94 | 94 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean_test_score | 0.727821 | 0.722241 | 0.721616 | 0.721006 | 0.715424 | 0.712324 | 0.711717 | 0.711086 | 0.70988 | 0.709874 | ... | 0.508371 | 0.508371 | 0.508371 | 0.50713 | 0.50713 | 0.50713 | 0.50713 | 0.50713 | 0.50713 | 0.50713 |
| param_columntransformer__countvectorizer__max_features | 1619 | 1014 | 688 | 1880 | 224 | 947 | 987 | 386 | 1997 | 1963 | ... | 928 | 1953 | 445 | 1397 | 776 | 1715 | 1562 | 1854 | 708 | 1631 |
| param_svc__gamma | 0.123539 | 0.165811 | 0.336735 | 0.101688 | 0.000976 | 0.126563 | 0.000508 | 0.000917 | 0.032324 | 0.000503 | ... | 18.053918 | 226.698857 | 40.024122 | 387.490568 | 268.760262 | 845.206099 | 358.257024 | 601.401895 | 984.435792 | 461.3012 |
| param_svc__C | 7551.390429 | 477.418069 | 8502.828976 | 2806.696859 | 9471.173025 | 9295.688135 | 559.066944 | 3590.67449 | 7951.972198 | 1520.347523 | ... | 7758.841886 | 9203.835651 | 3089.543297 | 2144.534114 | 7736.150115 | 2451.353961 | 1813.530052 | 1564.825306 | 2192.718242 | 389.888811 |
| mean_fit_time | 0.130273 | 0.136332 | 0.115882 | 0.132394 | 0.486029 | 0.168221 | 0.109244 | 0.269268 | 0.156212 | 0.18037 | ... | 0.120959 | 0.110708 | 0.116729 | 0.106839 | 0.105203 | 0.12935 | 0.111649 | 0.10962 | 0.119149 | 0.112679 |
5 rows × 100 columns
This is a bit fancy. What’s nice is that you can have it concentrate more on certain values by setting the distribution.
Advantages of RandomizedSearchCV#
Faster compared to
GridSearchCV.Adding parameters that do not influence the performance does not affect efficiency.
Works better when some parameters are more important than others.
In general, I recommend using
RandomizedSearchCVrather thanGridSearchCV.
Advantages of RandomizedSearchCV#
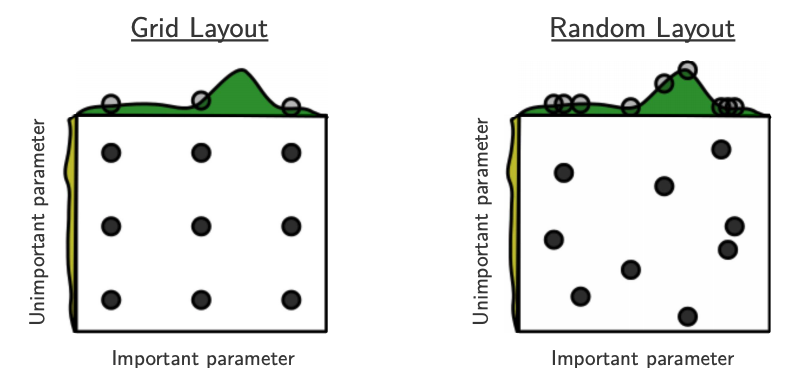
Source: Bergstra and Bengio, Random Search for Hyper-Parameter Optimization, JMLR 2012.
The yellow on the left shows how your scores are going to change when you vary the unimportant hyperparameter.
The green on the top shows how your scores are going to change when you vary the important hyperparameter.
You don’t know in advance which hyperparameters are important for your problem.
In the left figure, 6 of the 9 searches are useless because they are only varying the unimportant parameter.
In the right figure, all 9 searches are useful.
(Optional) Searching for optimal parameters with successive halving¶#
Successive halving is an iterative selection process where all candidates (the parameter combinations) are evaluated with a small amount of resources (e.g., small amount of training data) at the first iteration.
Checkout successive halving with grid search and random search.
from sklearn.experimental import enable_halving_search_cv # noqa
from sklearn.model_selection import HalvingRandomSearchCV
rsh = HalvingRandomSearchCV(
estimator=pipe_svm, param_distributions=param_dist, factor=2, random_state=123
)
rsh.fit(X_train, y_train)
HalvingRandomSearchCV(estimator=Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability',
'energy',
'instrumentalness',
'liveness',
'loudness',
'speechiness',
'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature',
'key']),
('passthrough',
'p...
('svc', SVC())]),
factor=2,
param_distributions={'columntransformer__countvectorizer__max_features': <scipy.stats._distn_infrastructure.rv_discrete_frozen object at 0x144397fd0>,
'svc__C': <scipy.stats._distn_infrastructure.rv_continuous_frozen object at 0x14465c1f0>,
'svc__gamma': <scipy.stats._distn_infrastructure.rv_continuous_frozen object at 0x1442ca9b0>},
random_state=123)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
HalvingRandomSearchCV(estimator=Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability',
'energy',
'instrumentalness',
'liveness',
'loudness',
'speechiness',
'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature',
'key']),
('passthrough',
'p...
('svc', SVC())]),
factor=2,
param_distributions={'columntransformer__countvectorizer__max_features': <scipy.stats._distn_infrastructure.rv_discrete_frozen object at 0x144397fd0>,
'svc__C': <scipy.stats._distn_infrastructure.rv_continuous_frozen object at 0x14465c1f0>,
'svc__gamma': <scipy.stats._distn_infrastructure.rv_continuous_frozen object at 0x1442ca9b0>},
random_state=123)Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('standardscaler',
StandardScaler(),
['acousticness',
'danceability', 'energy',
'instrumentalness',
'liveness', 'loudness',
'speechiness', 'tempo',
'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough',
['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])),
('svc', SVC())])ColumnTransformer(transformers=[('standardscaler', StandardScaler(),
['acousticness', 'danceability', 'energy',
'instrumentalness', 'liveness', 'loudness',
'speechiness', 'tempo', 'valence']),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
['time_signature', 'key']),
('passthrough', 'passthrough', ['mode']),
('countvectorizer',
CountVectorizer(max_features=100,
stop_words='english'),
'song_title')])['acousticness', 'danceability', 'energy', 'instrumentalness', 'liveness', 'loudness', 'speechiness', 'tempo', 'valence']
StandardScaler()
['time_signature', 'key']
OneHotEncoder(handle_unknown='ignore')
['mode']
passthrough
song_title
CountVectorizer(max_features=100, stop_words='english')
SVC()
results = pd.DataFrame(rsh.cv_results_)
results["params_str"] = results.params.apply(str)
results.drop_duplicates(subset=("params_str", "iter"), inplace=True)
results
| iter | n_resources | mean_fit_time | std_fit_time | mean_score_time | std_score_time | param_columntransformer__countvectorizer__max_features | param_svc__C | param_svc__gamma | params | ... | std_test_score | rank_test_score | split0_train_score | split1_train_score | split2_train_score | split3_train_score | split4_train_score | mean_train_score | std_train_score | params_str | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 20 | 0.004585 | 0.000258 | 0.002307 | 0.000221 | 1634 | 7129.653205 | 0.026777 | {'columntransformer__countvectorizer__max_features': 1634, 'svc__C': 7129.653205232272, 'svc__gamma': 0.02677733855112973} | ... | 0.333333 | 111 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | {'columntransformer__countvectorizer__max_features': 1634, 'svc__C': 7129.653205232272, 'svc__gamma': 0.02677733855112973} |
| 1 | 0 | 20 | 0.004293 | 0.000285 | 0.002259 | 0.000225 | 1222 | 5513.247691 | 5.698385 | {'columntransformer__countvectorizer__max_features': 1222, 'svc__C': 5513.247690828913, 'svc__gamma': 5.698384608345687} | ... | 0.367423 | 22 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | {'columntransformer__countvectorizer__max_features': 1222, 'svc__C': 5513.247690828913, 'svc__gamma': 5.698384608345687} |
| 2 | 0 | 20 | 0.004281 | 0.000274 | 0.002243 | 0.000224 | 1247 | 7800.377619 | 0.019382 | {'columntransformer__countvectorizer__max_features': 1247, 'svc__C': 7800.377619120792, 'svc__gamma': 0.019381838999846482} | ... | 0.333333 | 111 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | {'columntransformer__countvectorizer__max_features': 1247, 'svc__C': 7800.377619120792, 'svc__gamma': 0.019381838999846482} |
| 3 | 0 | 20 | 0.004291 | 0.000278 | 0.002258 | 0.000220 | 213 | 4809.419015 | 0.013707 | {'columntransformer__countvectorizer__max_features': 213, 'svc__C': 4809.41901484361, 'svc__gamma': 0.013706928443177698} | ... | 0.359784 | 144 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | {'columntransformer__countvectorizer__max_features': 213, 'svc__C': 4809.41901484361, 'svc__gamma': 0.013706928443177698} |
| 4 | 0 | 20 | 0.004284 | 0.000284 | 0.002259 | 0.000217 | 1042 | 6273.270093 | 0.003919 | {'columntransformer__countvectorizer__max_features': 1042, 'svc__C': 6273.270093376167, 'svc__gamma': 0.003919287722401839} | ... | 0.406202 | 97 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | {'columntransformer__countvectorizer__max_features': 1042, 'svc__C': 6273.270093376167, 'svc__gamma': 0.003919287722401839} |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 155 | 5 | 640 | 0.018674 | 0.000263 | 0.004572 | 0.000160 | 729 | 4943.40065 | 0.092454 | {'columntransformer__countvectorizer__max_features': 729, 'svc__C': 4943.400649628005, 'svc__gamma': 0.09245358900622544} | ... | 0.051925 | 10 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | {'columntransformer__countvectorizer__max_features': 729, 'svc__C': 4943.400649628005, 'svc__gamma': 0.09245358900622544} |
| 156 | 5 | 640 | 0.017854 | 0.000313 | 0.004704 | 0.000112 | 1383 | 2705.246646 | 0.173979 | {'columntransformer__countvectorizer__max_features': 1383, 'svc__C': 2705.246646103936, 'svc__gamma': 0.1739787032867638} | ... | 0.046116 | 9 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | {'columntransformer__countvectorizer__max_features': 1383, 'svc__C': 2705.246646103936, 'svc__gamma': 0.1739787032867638} |
| 157 | 5 | 640 | 0.017244 | 0.000211 | 0.004476 | 0.000055 | 440 | 5315.613738 | 0.17973 | {'columntransformer__countvectorizer__max_features': 440, 'svc__C': 5315.613738418384, 'svc__gamma': 0.17973005068132514} | ... | 0.043509 | 12 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | {'columntransformer__countvectorizer__max_features': 440, 'svc__C': 5315.613738418384, 'svc__gamma': 0.17973005068132514} |
| 158 | 6 | 1280 | 0.057830 | 0.000823 | 0.009009 | 0.000217 | 729 | 4943.40065 | 0.092454 | {'columntransformer__countvectorizer__max_features': 729, 'svc__C': 4943.400649628005, 'svc__gamma': 0.09245358900622544} | ... | 0.010715 | 19 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | {'columntransformer__countvectorizer__max_features': 729, 'svc__C': 4943.400649628005, 'svc__gamma': 0.09245358900622544} |
| 159 | 6 | 1280 | 0.052756 | 0.000467 | 0.010711 | 0.000216 | 1383 | 2705.246646 | 0.173979 | {'columntransformer__countvectorizer__max_features': 1383, 'svc__C': 2705.246646103936, 'svc__gamma': 0.1739787032867638} | ... | 0.026620 | 11 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | {'columntransformer__countvectorizer__max_features': 1383, 'svc__C': 2705.246646103936, 'svc__gamma': 0.1739787032867638} |
160 rows × 26 columns
(Optional) Fancier methods#
Both
GridSearchCVandRandomizedSearchCVdo each trial independently.What if you could learn from your experience, e.g. learn that
max_depth=3is bad?That could save time because you wouldn’t try combinations involving
max_depth=3in the future.
We can do this with
scikit-optimize, which is a completely different package fromscikit-learnIt uses a technique called “model-based optimization” and we’ll specifically use “Bayesian optimization”.
In short, it uses machine learning to predict what hyperparameters will be good.
Machine learning on machine learning!
This is an active research area and there are sophisticated packages for this.
Here are some examples
❓❓ Questions for you#
(iClicker) Exercise 6.1#
iClicker cloud join link: https://join.iclicker.com/SNBF
Select all of the following statements which are TRUE.
(A) If you get best results at the edges of your parameter grid, it might be a good idea to adjust the range of values in your parameter grid.
(B) Grid search is guaranteed to find the best hyperparameter values.
(C) It is possible to get different hyperparameters in different runs of
RandomizedSearchCV.
Questions for class discussion (hyperparameter optimization)#
Suppose you have 10 hyperparameters, each with 4 possible values. If you run
GridSearchCVwith this parameter grid, how many cross-validation experiments will be carried out?Suppose you have 10 hyperparameters and each takes 4 values. If you run
RandomizedSearchCVwith this parameter grid withn_iter=20, how many cross-validation experiments will be carried out?
Optimization bias/Overfitting of the validation set#
Overfitting of the validation error#
Why do we need to evaluate the model on the test set in the end?
Why not just use cross-validation on the whole dataset?
While carrying out hyperparameter optimization, we usually try over many possibilities.
If our dataset is small and if your validation set is hit too many times, we suffer from optimization bias or overfitting the validation set.
Optimization bias of parameter learning#
Overfitting of the training error
An example:
During training, we could search over tons of different decision trees.
So we can get “lucky” and find a tree with low training error by chance.
Optimization bias of hyper-parameter learning#
Overfitting of the validation error
An example:
Here, we might optimize the validation error over 1000 values of
max_depth.One of the 1000 trees might have low validation error by chance.
(Optional) Example 1: Optimization bias#
Consider a multiple-choice (a,b,c,d) “test” with 10 questions:
If you choose answers randomly, expected grade is 25% (no bias).
If you fill out two tests randomly and pick the best, expected grade is 33%.
Optimization bias of ~8%.
If you take the best among 10 random tests, expected grade is ~47%.
If you take the best among 100, expected grade is ~62%.
If you take the best among 1000, expected grade is ~73%.
If you take the best among 10000, expected grade is ~82%.
You have so many “chances” that you expect to do well.
But on new questions the “random choice” accuracy is still 25%.
# (Optional) Code attribution: Rodolfo Lourenzutti
number_tests = [1, 2, 10, 100, 1000, 10000]
for ntests in number_tests:
y = np.zeros(10000)
for i in range(10000):
y[i] = np.max(np.random.binomial(10.0, 0.25, ntests))
print(
"The expected grade among the best of %d tests is : %0.2f"
% (ntests, np.mean(y) / 10.0)
)
The expected grade among the best of 1 tests is : 0.25
The expected grade among the best of 2 tests is : 0.33
The expected grade among the best of 10 tests is : 0.47
The expected grade among the best of 100 tests is : 0.62
The expected grade among the best of 1000 tests is : 0.73
The expected grade among the best of 10000 tests is : 0.83
(Optional) Example 2: Optimization bias#
If we instead used a 100-question test then:
Expected grade from best over 1 randomly-filled test is 25%.
Expected grade from best over 2 randomly-filled test is ~27%.
Expected grade from best over 10 randomly-filled test is ~32%.
Expected grade from best over 100 randomly-filled test is ~36%.
Expected grade from best over 1000 randomly-filled test is ~40%.
Expected grade from best over 10000 randomly-filled test is ~43%.
The optimization bias grows with the number of things we try.
“Complexity” of the set of models we search over.
But, optimization bias shrinks quickly with the number of examples.
But it’s still non-zero and growing if you over-use your validation set!
# (Optional) Code attribution: Rodolfo Lourenzutti
number_tests = [1, 2, 10, 100, 1000, 10000]
for ntests in number_tests:
y = np.zeros(10000)
for i in range(10000):
y[i] = np.max(np.random.binomial(100.0, 0.25, ntests))
print(
"The expected grade among the best of %d tests is : %0.2f"
% (ntests, np.mean(y) / 100.0)
)
The expected grade among the best of 1 tests is : 0.25
The expected grade among the best of 2 tests is : 0.27
The expected grade among the best of 10 tests is : 0.32
The expected grade among the best of 100 tests is : 0.36
The expected grade among the best of 1000 tests is : 0.40
The expected grade among the best of 10000 tests is : 0.43
Optimization bias on the Spotify dataset#
X_train_tiny, X_test_big, y_train_tiny, y_test_big = train_test_split(
X_spotify, y_spotify, test_size=0.99, random_state=42
)
X_train_tiny.shape
(20, 14)
X_train_tiny.head()
| acousticness | danceability | duration_ms | energy | instrumentalness | key | liveness | loudness | mode | speechiness | tempo | time_signature | valence | song_title | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 130 | 0.055100 | 0.547 | 251093 | 0.643 | 0.000000 | 1 | 0.2670 | -8.904 | 1 | 0.2270 | 143.064 | 4.0 | 0.1870 | My Sub (Pt. 2: The Jackin') - Album Version (Edited) |
| 1687 | 0.000353 | 0.420 | 210240 | 0.929 | 0.000747 | 7 | 0.1220 | -3.899 | 0 | 0.1210 | 127.204 | 4.0 | 0.3180 | Chop Suey! |
| 871 | 0.314000 | 0.430 | 193427 | 0.734 | 0.000286 | 9 | 0.0808 | -10.043 | 0 | 0.1020 | 133.992 | 4.0 | 0.0537 | Able to See Me |
| 1123 | 0.082100 | 0.725 | 246653 | 0.711 | 0.000000 | 10 | 0.0931 | -4.544 | 1 | 0.0335 | 93.003 | 4.0 | 0.4760 | Mi Tesoro (feat. Nicky Jam) |
| 1396 | 0.286000 | 0.616 | 236960 | 0.387 | 0.000000 | 9 | 0.2770 | -6.079 | 0 | 0.0335 | 81.856 | 4.0 | 0.4700 | All in Vain |
pipe = make_pipeline(preprocessor, SVC())
from sklearn.model_selection import RandomizedSearchCV
param_grid = {
"svc__gamma": 10.0 ** np.arange(-20, 10),
"svc__C": 10.0 ** np.arange(-20, 10),
}
print("Grid size: %d" % (np.prod(list(map(len, param_grid.values())))))
param_grid
Grid size: 900
{'svc__gamma': array([1.e-20, 1.e-19, 1.e-18, 1.e-17, 1.e-16, 1.e-15, 1.e-14, 1.e-13,
1.e-12, 1.e-11, 1.e-10, 1.e-09, 1.e-08, 1.e-07, 1.e-06, 1.e-05,
1.e-04, 1.e-03, 1.e-02, 1.e-01, 1.e+00, 1.e+01, 1.e+02, 1.e+03,
1.e+04, 1.e+05, 1.e+06, 1.e+07, 1.e+08, 1.e+09]),
'svc__C': array([1.e-20, 1.e-19, 1.e-18, 1.e-17, 1.e-16, 1.e-15, 1.e-14, 1.e-13,
1.e-12, 1.e-11, 1.e-10, 1.e-09, 1.e-08, 1.e-07, 1.e-06, 1.e-05,
1.e-04, 1.e-03, 1.e-02, 1.e-01, 1.e+00, 1.e+01, 1.e+02, 1.e+03,
1.e+04, 1.e+05, 1.e+06, 1.e+07, 1.e+08, 1.e+09])}
random_search = RandomizedSearchCV(
pipe, param_distributions=param_grid, n_jobs=-1, n_iter=900, cv=5, random_state=123
)
random_search.fit(X_train_tiny, y_train_tiny);
pd.DataFrame(random_search.cv_results_)[
[
"mean_test_score",
"param_svc__gamma",
"param_svc__C",
"mean_fit_time",
"rank_test_score",
]
].set_index("rank_test_score").sort_index().T
| rank_test_score | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 888 | 888 | 888 | 888 | 888 | 888 | 888 | 888 | 888 | 900 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean_test_score | 0.65 | 0.65 | 0.65 | 0.65 | 0.65 | 0.65 | 0.65 | 0.65 | 0.65 | 0.65 | ... | 0.55 | 0.55 | 0.55 | 0.55 | 0.55 | 0.55 | 0.55 | 0.55 | 0.55 | 0.5 |
| param_svc__gamma | 0.0 | 0.01 | 0.1 | 1.0 | 10.0 | 100.0 | 1000.0 | 10000.0 | 100000.0 | 1000000.0 | ... | 0.1 | 0.1 | 0.0 | 0.0 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.0 |
| param_svc__C | 0.0 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | ... | 100000.0 | 10000000.0 | 1000000000.0 | 1000000000.0 | 1.0 | 1000.0 | 10.0 | 1000000000.0 | 1000000.0 | 100000000.0 |
| mean_fit_time | 0.026514 | 0.005514 | 0.006395 | 0.007606 | 0.007719 | 0.005667 | 0.007007 | 0.008214 | 0.006482 | 0.006983 | ... | 0.00959 | 0.00889 | 0.008704 | 0.01155 | 0.008994 | 0.009918 | 0.008176 | 0.00663 | 0.006731 | 0.008373 |
4 rows × 900 columns
Given the results: one might claim that we found a model that performs with 0.8 accuracy on our dataset.
Do we really believe that 0.80 is a good estimate of our test data?
Do we really believe that
gamma=0.0 and C=1_000_000_000 are the best hyperparameters?
Let’s find out the test score with this best model.
random_search.score(X_test, y_test)
0.5024752475247525
The results above are overly optimistic.
because our training data is very small and so our validation splits in cross validation would be small.
because of the small dataset and the fact that we hit the small validation set 900 times and it’s possible that we got lucky on the validation set!
As we suspected, the best cross-validation score is not a good estimate of our test data; it is overly optimistic.
We can trust this test score because the test set is of good size.
X_test_big.shape
(1997, 14)
Overfitting of the validation data#
The following plot demonstrates what happens during overfitting of the validation data.

Thus, not only can we not trust the cv scores, we also cannot trust cv’s ability to choose of the best hyperparameters.
Why do we need a test set?#
This is why we need a test set.
The frustrating part is that if our dataset is small then our test set is also small 😔.
But we don’t have a lot of better alternatives, unfortunately, if we have a small dataset.
When test score is much lower than CV score#
What to do if your test score is much lower than your cross-validation score:
Try simpler models and use the test set a couple of times; it’s not the end of the world.
Communicate this clearly when you report the results.
Large datasets solve many of these problems#
With infinite amounts of training data, overfitting would not be a problem and you could have your test score = your train score.
Overfitting happens because you only see a bit of data and you learn patterns that are overly specific to your sample.
If you saw “all” the data, then the notion of “overly specific” would not apply.
So, more data will make your test score better and robust.
❓❓ Questions for you#
Attribution: From Mark Schmidt’s notes
Exercise 6.2#
Would you trust the model?
You have a dataset and you give me 1/10th of it. The dataset given to me is rather small and so I split it into 96% train and 4% validation split. I carry out hyperparameter optimization using a single 4% validation split and report validation accuracy of 0.97. Would it classify the rest of the data with similar accuracy?
Probably
Probably not
Final comments and summary#
Automated hyperparameter optimization#
Advantages
reduce human effort
less prone to error and improve reproducibility
data-driven approaches may be effective
Disadvantages
may be hard to incorporate intuition
be careful about overfitting on the validation set
Often, especially on typical datasets, we get back scikit-learn’s default hyperparameter values. This means that the defaults are well chosen by scikit-learn developers!
The problem of finding the best values for the important hyperparameters is tricky because
You may have a lot of them (e.g. deep learning).
You may have multiple hyperparameters which may interact with each other in unexpected ways.
The best settings depend on the specific data/problem.
Optional readings and resources#
Preventing “overfitting” of cross-validation data by Andrew Ng