
Lecture 19: Multi-class classification and introduction to computer vision#
Imports and LO#
Imports#
import glob
import copy
import os, sys
import time
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
sys.path.append(os.path.join(os.path.abspath(".."), "code"))
from plotting_functions import *
from sklearn import datasets
from sklearn.dummy import DummyClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import (
classification_report,
confusion_matrix
)
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline, make_pipeline
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline, make_pipeline
from sklearn.preprocessing import StandardScaler
DATA_DIR = os.path.join(os.path.abspath(".."), "data/")
Learning objectives#
Apply classifiers to multi-class classification algorithms.
Explain the role of neural networks in machine learning, and the pros/cons of using them.
Explain why the methods we’ve learned previously would not be effective on image data.
Apply pre-trained neural networks to classification and regression problems.
Utilize pre-trained networks as feature extractors and combine them with models we’ve learned previously.
❓❓ Questions for you#
iClicker Exercise 19.1#
Select all of the following statements which are TRUE.
(A) It’s possible to use word2vec embedding representations for text classification instead of bag-of-words representation.
(B) The topic model approach we used in the last lecture, Latent Dirichlet Allocation (LDA), is an unsupervised approach.
(C) In an LDA topic model, the same word can be associated with two different topics with high probability.
(D) In an LDA topic model, a document is a mixture of multiple topics.
(E) If I train a topic model on a large collection of news articles with K = 10, I would get 10 topic labels (e.g., sports, culture, politics, finance) as output.
Multi-class classification#
So far we have been talking about binary classification
Can we use these classifiers when there are more than two classes?
“ImageNet” computer vision competition, for example, has 1000 classes
Can we use decision trees or KNNs for multi-class classification?
What about logistic regression and Linear SVMs?
Some models naturally extend to multiclass classification.
If they don’t a common technique is to reduce multiclass classication into several instances of binary classification problems.
Two kind of “hacky” ways to reduce multi-class classification into binary classification:
the one-vs.-rest approach
the one-vs.-one approach
import mglearn
from sklearn.datasets import make_blobs
%matplotlib inline
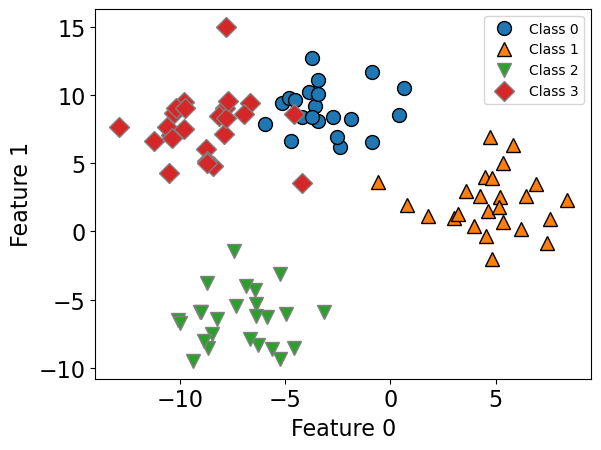
X, y = make_blobs(centers=4, n_samples=120, cluster_std=2.0, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=123
)
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.legend(["Class 0", "Class 1", "Class 2", "Class 3"], fontsize=10);
lr = LogisticRegression()
lr.fit(X_train, y_train)
LogisticRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LogisticRegression()
lr.score(X_train, y_train)
0.96875
lr.score(X_test, y_test)
0.9583333333333334
Logisitic regression learns a coefficient associated with each feature and each class.
lr.coef_
array([[ 0.29324459, 0.7588186 ],
[ 1.17054987, -0.31908384],
[-0.3298721 , -0.84698489],
[-1.13392236, 0.40725012]])
For each class there is an intercept.
lr.intercept_
array([-0.64417243, 5.10584063, 1.09706504, -5.55873323])
Predictions#
Predictions are made by
getting raw scores for each class
applying softmax instead of sigmoid to get probability distribution over a number of classes
picking the class with the highest prediction probability
Sigmoid vs. Softmax#
For binary classification, we used the sigmoid function, which “squashes” the raw model output from any number to the range \([0,1]\) using the following formula, where \(x\) is the raw model output. $\(\frac{1}{1+e^{-x}}\)$
For multiclass classification, instead of sigmoid, we use softmax, which normalizes a set of raw scores into probabilities.
It basically makes sure all the outputs are probabilities between 0 and 1, and that they all sum to 1.
We can examine class probabilities by calling predict_proba on an example.
lr.predict_proba(X_test)[0]
array([4.10793260e-03, 2.31298589e-08, 5.83848728e-06, 9.95886206e-01])
lr.classes_
array([0, 1, 2, 3])
# The prediction here is class 3 because it has the highest predict proba score of 0.995
lr.predict(X_test)[0]
3
For models such as SVMs which do not naturally extend to multiclass classification, a common technique is to reduce multiclass classication into several instances of binary classification problems.
Two kind of “hacky” ways to reduce multi-class classification into binary classification:
the one-vs.-rest approach
the one-vs.-one approach
Check out appendixB for more details.
Introduction to neural networks#
Very popular these days under the name deep learning.
Neural networks apply a sequence of transformations on your input data.
They can be viewed a generalization of linear models where we apply a series of transformations.
Here is graphical representation of a logistic regression model.
We have 4 features: x[0], x[1], x[2], x[3]
import mglearn
mglearn.plots.plot_logistic_regression_graph()

Below we are adding one “layer” of transformations in between features and the target.
We are repeating the the process of computing the weighted sum multiple times.
The hidden units (e.g., h[1], h[2], …) represent the intermediate processing steps.
mglearn.plots.plot_single_hidden_layer_graph()

Now we are adding one more layer of transformations.
mglearn.plots.plot_two_hidden_layer_graph()

At a very high level you can also think of them as
Pipelinesinsklearn.A neural network is a model that’s sort of like its own pipeline
It involves a series of transformations (“layers”) internally.
The output is the prediction.
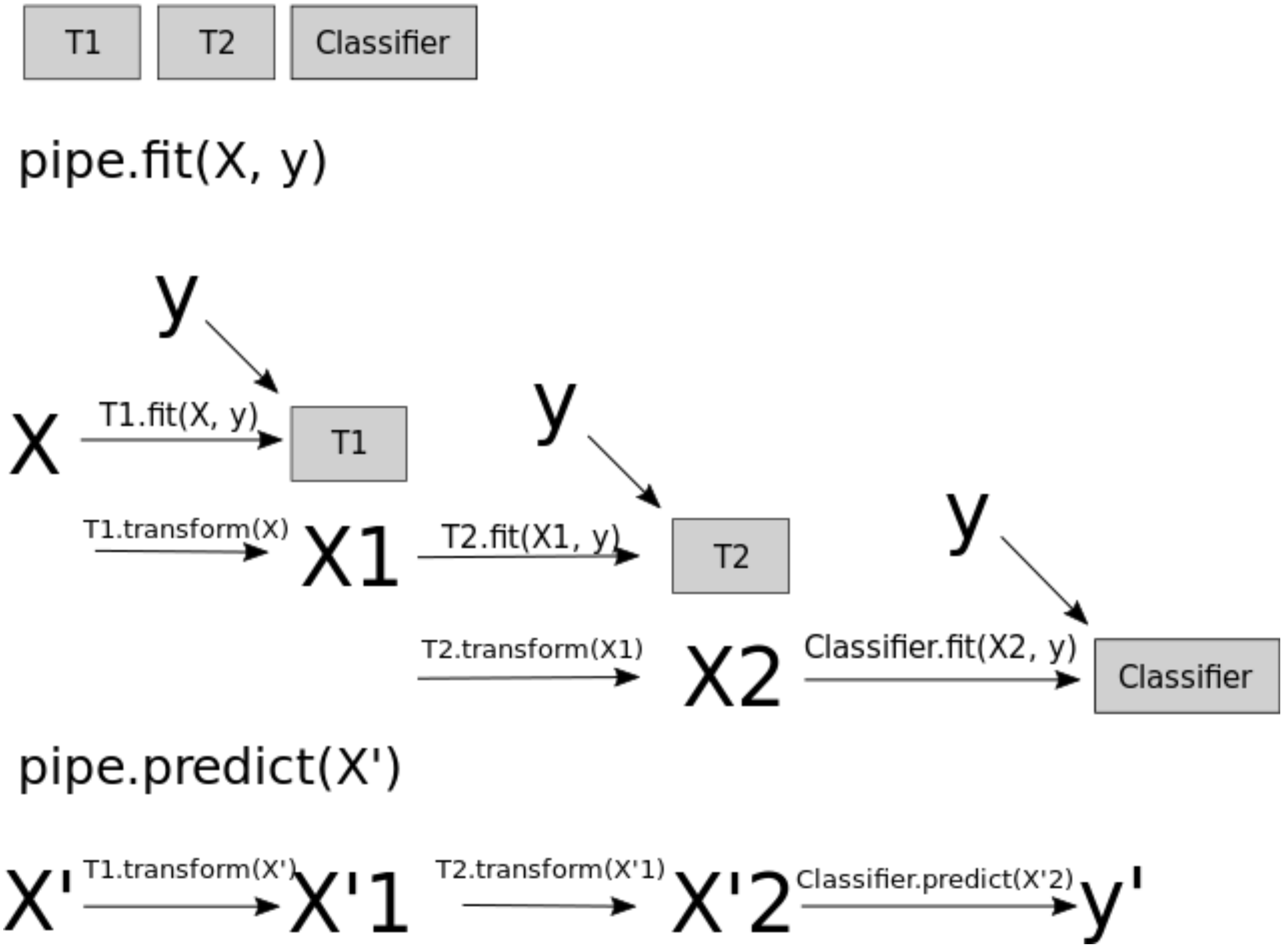
Important question: how many features before/after transformation.
e.g. scaling doesn’t change the number of features
OHE increases the number of features
With a neural net, you specify the number of features after each transformation.
In the above, it goes from 4 to 3 to 3 to 1.
To make them really powerful compared to the linear models, we apply a non-linear function to the weighted sum for each hidden node.
Terminology#
Neural network = neural net
Deep learning ~ using neural networks
Why neural networks?#
They can learn very complex functions.
The fundamental tradeoff is primarily controlled by the number of layers and layer sizes.
More layers / bigger layers –> more complex model.
You can generally get a model that will not underfit.
Why neural networks?#
The work really well for structured data:
1D sequence, e.g. timeseries, language
2D image
3D image or video
They’ve had some incredible successes in the last 10 years.
Transfer learning (coming later today) is really useful.
Why not neural networks?#
Often they require a lot of data.
They require a lot of compute time, and, to be faster, specialized hardware called GPUs.
They have huge numbers of hyperparameters are a huge pain to tune.
Think of each layer having hyperparameters, plus some overall hyperparameters.
Being slow compounds this problem.
They are not interpretable.
Why not neural networks?#
When you call
fit, you are not guaranteed to get the optimal.There are now a bunch of hyperparameters specific to
fit, rather than the model.You never really know if
fitwas successful or not.You never really know if you should have run
fitfor longer.
I don’t recommend training them on your own without further training
Take CPSC 340 and other courses if you’re interested.
I’ll show you some ways to use neural networks without calling
fit.
Deep learning software#
scikit-learn has MLPRegressor and MLPClassifier but they aren’t very flexible.
In general you’ll want to leave the scikit-learn ecosystem when using neural networks.
Fun fact: these classes were contributed to scikit-learn by a UBC graduate student.
There’s been a lot of deep learning software out there.
The current big players are:
Both are heavily used in industry.
If interested, see comparison of deep learning software.
Break (5 min)#

Introduction to computer vision#
Computer vision refers to understanding images/videos, usually using ML/AI.
Computer vision has many tasks of interest:
image classification: is this a cat or a dog?
object localization: where is the cat in this image?
object detection: What are the various objects in the image?
instance segmentation: What are the shapes of these various objects in the image?
and much more…
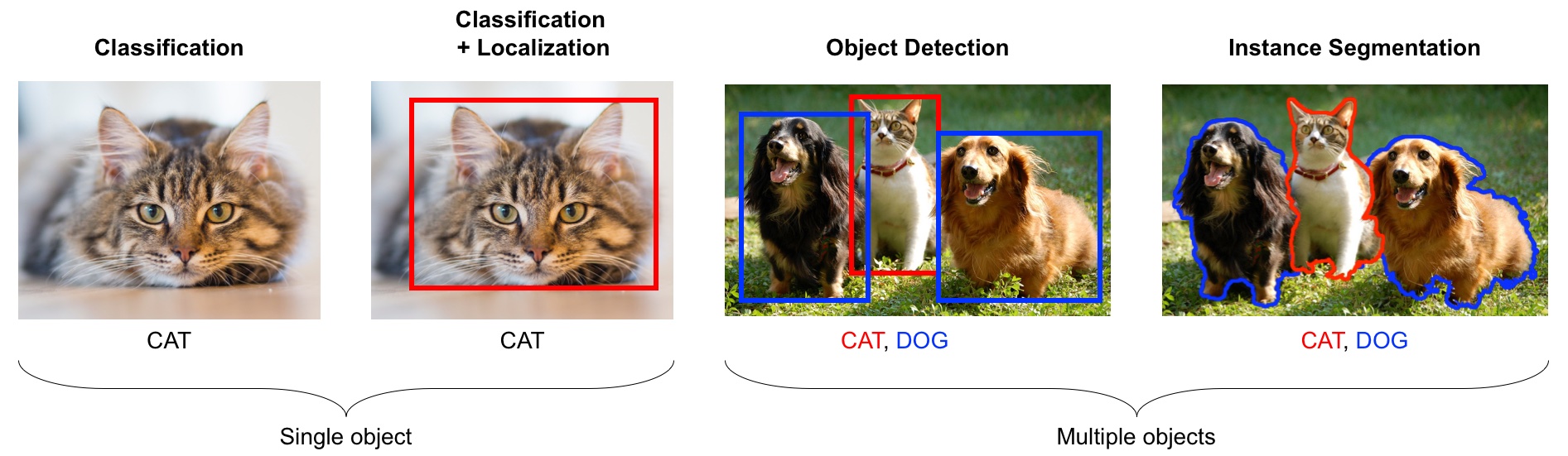
Source: https://learning.oreilly.com/library/view/python-advanced-guide/9781789957211/
In the last decade this field has been dominated by deep learning.
We will explore image classification.
Dataset#
For this demonstration I’m using a subset of Kaggle’s Animal Faces dataset.
Usually structured data such as this one doesn’t come in CSV files.
Also, if you are working on image datasets in the real world, they are going to be huge datasets and you do not want to load the full dataset at once in the memory.
So usually you work on small batches.
You are not expected to understand all the code below. But I’m including it for your reference.
# Attribution: [Code from PyTorch docs](https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html?highlight=transfer%20learning)
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torch.optim import lr_scheduler
from torchvision import datasets, models, transforms, utils
IMAGE_SIZE = 200
data_transforms_bw = {
"train": transforms.Compose(
[
transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor(),
]
),
"valid": transforms.Compose(
[
transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor(),
]
),
}
data_dir = DATA_DIR + "animal_faces"
image_datasets_bw = {
x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms_bw[x])
for x in ["train", "valid"]
}
dataloaders_bw = {
x: torch.utils.data.DataLoader(
image_datasets_bw[x], batch_size=24, shuffle=True, num_workers=4
)
for x in ["train", "valid"]
}
dataset_sizes = {x: len(image_datasets_bw[x]) for x in ["train", "valid"]}
class_names = image_datasets_bw["train"].classes
# Get a batch of training data
inputs_bw, classes = next(iter(dataloaders_bw["train"]))
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
plt.figure(figsize=(10, 8)); plt.axis("off"); plt.title("Sample Training Images")
plt.imshow(np.transpose(utils.make_grid(inputs_bw, padding=1, normalize=True),(1, 2, 0)));

print(f"Classes: {image_datasets_bw['train'].classes}")
print(f"Class count: {image_datasets_bw['train'].targets.count(0)}, {image_datasets_bw['train'].targets.count(1)}, {image_datasets_bw['train'].targets.count(2)}")
print(f"Samples:", len(image_datasets_bw["train"]))
print(f"First sample: {image_datasets_bw['train'].samples[0]}")
Classes: ['cat', 'dog', 'wild']
Class count: 50, 50, 50
Samples: 150
First sample: ('/Users/gtoti/Documents/GitHub/cpsc330-2024W1/lectures/data/animal_faces/train/cat/flickr_cat_000002.jpg', 0)
Logistic regression with flattened representation of images#
How can we train traditional ML models designed for tabular data on image data?
Let’s flatten the images and trained Logistic regression.
# This code flattens the images in train and validation sets.
# Again you're not expected to understand all the code.
flatten_transforms = transforms.Compose([
transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor(),
transforms.Lambda(torch.flatten)])
train_flatten = torchvision.datasets.ImageFolder(root=DATA_DIR + 'animal_faces/train', transform=flatten_transforms)
valid_flatten = torchvision.datasets.ImageFolder(root=DATA_DIR + 'animal_faces/valid', transform=flatten_transforms)
train_dataloader = torch.utils.data.DataLoader(train_flatten, batch_size=150, shuffle=True)
valid_dataloader = torch.utils.data.DataLoader(valid_flatten, batch_size=150, shuffle=True)
flatten_train, y_train = next(iter(train_dataloader))
flatten_valid, y_valid = next(iter(valid_dataloader))
flatten_train.numpy().shape
(150, 40000)
We have flattened representation (40_000 columns) for all 150 training images.
Let’s train dummy classifier and logistic regression on these flattened images.
dummy = DummyClassifier()
dummy.fit(flatten_train.numpy(), y_train)
dummy.score(flatten_train.numpy(), y_train)
0.3333333333333333
dummy.score(flatten_valid.numpy(), y_train)
0.3333333333333333
lr_flatten_pipe = make_pipeline(StandardScaler(), LogisticRegression(max_iter=3000))
lr_flatten_pipe.fit(flatten_train.numpy(), y_train)
Pipeline(steps=[('standardscaler', StandardScaler()),
('logisticregression', LogisticRegression(max_iter=3000))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('standardscaler', StandardScaler()),
('logisticregression', LogisticRegression(max_iter=3000))])StandardScaler()
LogisticRegression(max_iter=3000)
lr_flatten_pipe.score(flatten_train.numpy(), y_train)
1.0
lr_flatten_pipe.score(flatten_valid.numpy(), y_valid)
0.6666666666666666
The model is overfitting.
We are getting not so great validation results.
Why flattening images is a bad idea?
There is some structure in this data.
By “flattening” the image we throw away useful information.
This is what we see.
plt.rcParams["image.cmap"] = "gray"
plt.figure(figsize=(3, 3)); plt.axis("off"); plt.title("Example image")
plt.imshow(flatten_train[4].reshape(200,200));

This is what the computer sees:
flatten_train[4].numpy()
array([0.36862746, 0.39607844, 0.52156866, ..., 0.99607843, 0.99607843,
0.99607843], dtype=float32)
Hard to classify this!
Convolutional neural networks (CNNs) can take in images without flattening them.
We won’t cover CNNs here, but they are in CPSC 340.
Transfer learning#
In practice, very few people train an entire CNN from scratch because it requires a large dataset, powerful computers, and a huge amount of human effort to train the model.
Instead, a common practice is to download a pre-trained model and fine tune it for your task.
This is called transfer learning.
Transfer learning is one of the most common techniques used in the context of computer vision and natural language processing.
In the last lecture we used pre-trained embeddings to create text representations.
There are many deep learning architectures out there that have been very successful across a wide range of problem, e.g.: AlexNet, VGG, ResNet, Inception, MobileNet, etc.
Many of these are trained on famous datasets such as ImageNet (which contains 1.2 million labelled images with 1000 categories)
ImageNet#
ImageNet is an image dataset that became a very popular benchmark in the field ~10 years ago.
There are 14 million images and 1000 classes.
Here are some example classes.
Wikipedia article on ImageNet
with open(DATA_DIR + "imagenet_classes.txt") as f:
classes = [line.strip() for line in f.readlines()]
classes[100:110]
['black swan, Cygnus atratus',
'tusker',
'echidna, spiny anteater, anteater',
'platypus, duckbill, duckbilled platypus, duck-billed platypus, Ornithorhynchus anatinus',
'wallaby, brush kangaroo',
'koala, koala bear, kangaroo bear, native bear, Phascolarctos cinereus',
'wombat',
'jellyfish',
'sea anemone, anemone',
'brain coral']
The idea of transfer learning is instead of developing a machine learning model from scratch, you use these available pre-trained models for your tasks either directly or by fine tuning them.
There are three common ways to use transfer learning in computer vision
Using pre-trained models out-of-the-box
Using pre-trained models as feature extractor and training your own model with these features
Starting with weights of pre-trained models and fine-tuning the weights for your task.
We will explore the first two approaches.
Using pre-trained models out-of-the-box#
Remember this example I showed you in the intro video (our very first lecture)?
We used a pre-trained model vgg16 which is trained on the ImageNet data.
We preprocess the given image.
We get prediction from this pre-trained model on a given image along with prediction probabilities.
For a given image, this model will spit out one of the 1000 classes from ImageNet.
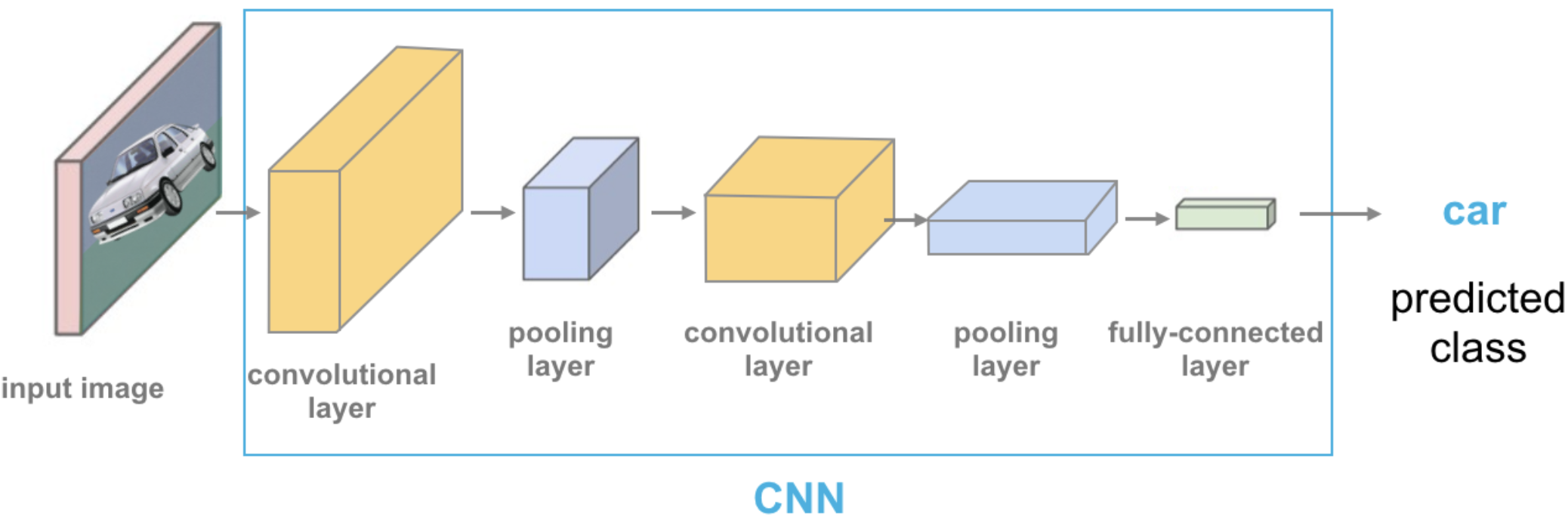
Source: https://cezannec.github.io/Convolutional_Neural_Networks/
def classify_image(img, topn = 4):
clf = vgg16(weights='VGG16_Weights.DEFAULT') # initialize the classifier with VGG16 weights
preprocess = transforms.Compose([
transforms.Resize(299),
transforms.CenterCrop(299),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),])
with open(DATA_DIR + 'imagenet_classes.txt') as f:
classes = [line.strip() for line in f.readlines()]
img_t = preprocess(img)
batch_t = torch.unsqueeze(img_t, 0)
clf.eval()
output = clf(batch_t)
_, indices = torch.sort(output, descending=True)
probabilities = torch.nn.functional.softmax(output, dim=1)
d = {'Class': [classes[idx] for idx in indices[0][:topn]],
'Probability score': [np.round(probabilities[0, idx].item(),3) for idx in indices[0][:topn]]}
df = pd.DataFrame(d, columns = ['Class','Probability score'])
return df
import torch
from PIL import Image
from torchvision import transforms
from torchvision.models import vgg16
# Predict labels with associated probabilities for unseen images
images = glob.glob(DATA_DIR + "test_images/*.*")
for image in images:
img = Image.open(image)
img.load()
plt.imshow(img)
plt.show()
df = classify_image(img)
print(df.to_string(index=False))
print("--------------------------------------------------------------")

Class Probability score
tiger cat 0.353
tabby, tabby cat 0.207
lynx, catamount 0.050
Pembroke, Pembroke Welsh corgi 0.046
--------------------------------------------------------------
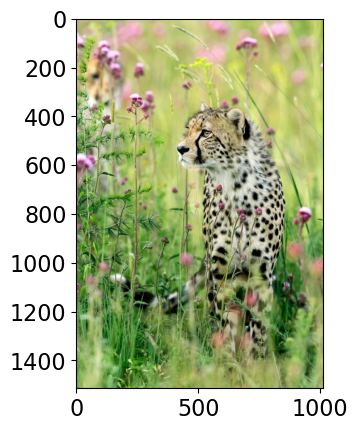
Class Probability score
cheetah, chetah, Acinonyx jubatus 0.983
leopard, Panthera pardus 0.012
jaguar, panther, Panthera onca, Felis onca 0.004
snow leopard, ounce, Panthera uncia 0.001
--------------------------------------------------------------

Class Probability score
macaque 0.714
patas, hussar monkey, Erythrocebus patas 0.122
proboscis monkey, Nasalis larvatus 0.098
guenon, guenon monkey 0.017
--------------------------------------------------------------
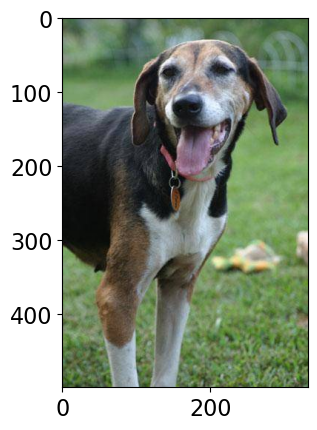
Class Probability score
Walker hound, Walker foxhound 0.580
English foxhound 0.091
EntleBucher 0.080
beagle 0.065
--------------------------------------------------------------
We got these predictions without “doing the ML ourselves”.
We are using pre-trained
vgg16model which is available intorchvision.torchvisionhas many such pre-trained models available that have been very successful across a wide range of tasks: AlexNet, VGG, ResNet, Inception, MobileNet, etc.Many of these models have been pre-trained on famous datasets like ImageNet.
So if we use them out-of-the-box, they will give us one of the ImageNet classes as classification.
Let’s see what labels this pre-trained model give us for some images which are very different from the training set.
# Predict labels with associated probabilities for unseen images
images = glob.glob(DATA_DIR + "UBC_img/*.*")
for image in images:
img = Image.open(image)
img.load()
plt.imshow(img)
plt.show()
df = classify_image(img)
print(df.to_string(index=False))
print("--------------------------------------------------------------")

Class Probability score
sandbar, sand bar 0.421
seashore, coast, seacoast, sea-coast 0.157
breakwater, groin, groyne, mole, bulwark, seawall, jetty 0.071
lakeside, lakeshore 0.036
--------------------------------------------------------------

Class Probability score
obelisk 0.104
pole 0.077
bell cote, bell cot 0.057
sliding door 0.045
--------------------------------------------------------------

Class Probability score
fig 0.637
pomegranate 0.193
grocery store, grocery, food market, market 0.041
crate 0.023
--------------------------------------------------------------

Class Probability score
castle 0.056
altar 0.056
fountain 0.051
park bench 0.049
--------------------------------------------------------------

Class Probability score
totem pole 0.987
pole 0.011
sundial 0.000
pedestal, plinth, footstall 0.000
--------------------------------------------------------------
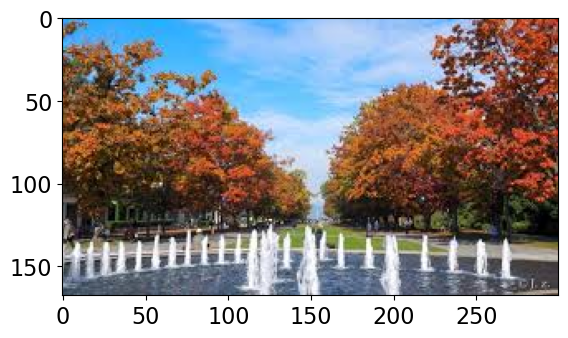
Class Probability score
lakeside, lakeshore 0.568
worm fence, snake fence, snake-rail fence, Virginia fence 0.180
boathouse 0.101
mobile home, manufactured home 0.017
--------------------------------------------------------------

Class Probability score
toilet seat 0.171
safety pin 0.060
bannister, banister, balustrade, balusters, handrail 0.039
bubble 0.035
--------------------------------------------------------------

Class Probability score
patio, terrace 0.213
fountain 0.164
lakeside, lakeshore 0.097
sundial 0.088
--------------------------------------------------------------
It’s not doing very well here because ImageNet don’t have proper classes for these images.
Here we are using pre-trained models out-of-the-box.
Can we use pre-trained models for our own classification problem with our classes?
Yes!!
Using pre-trained models as feature extractor#
Let’s use pre-trained models to extract features.
We will pass our specific data through a pre-trained network to get a feature vector for each example in the data.
The feature vector is usually extracted from the last layer, before the classification layer from the pre-trained network.
You can think of each layer a transformer applying some transformations on the input received to that later.
Source: https://cezannec.github.io/Convolutional_Neural_Networks/
Once we extract these feature vectors for all images in our training data, we can train a machine learning classifier such as logistic regression or random forest.
This classifier will be trained on our classes using feature representations extracted from the pre-trained models.
Let’s try this out.
It’s better to train such models with GPU. Since our dataset is quite small, we won’t have problems running it on a CPU.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device.type}")
Using device: cpu
Reading the data#
Let’s read the data. Before we just used 1 colour channel because we wanted to flatten the representation.
Here, I’m using all three colour channels.
Let’s read and prepare the data. (You are not expected to understand this code.)
# Attribution: [Code from PyTorch docs](https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html?highlight=transfer%20learning)
IMAGE_SIZE = 200
BATCH_SIZE = 64
data_transforms = {
"train": transforms.Compose(
[
# transforms.RandomResizedCrop(224),
# transforms.RandomHorizontalFlip(),
transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),
transforms.ToTensor(),
#transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]),
]
),
"valid": transforms.Compose(
[
# transforms.Resize(256),
# transforms.CenterCrop(224),
transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),
transforms.ToTensor(),
# transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]),
]
),
}
data_dir = DATA_DIR + "animal_faces"
image_datasets = {
x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x])
for x in ["train", "valid"]
}
dataloaders = {
x: torch.utils.data.DataLoader(
image_datasets[x], batch_size=BATCH_SIZE, shuffle=True, num_workers=4
)
for x in ["train", "valid"]
}
dataset_sizes = {x: len(image_datasets[x]) for x in ["train", "valid"]}
class_names = image_datasets["train"].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Get a batch of training data
inputs, classes = next(iter(dataloaders["train"]))
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
plt.figure(figsize=(10, 8)); plt.axis("off"); plt.title("Sample Training Images")
plt.imshow(np.transpose(utils.make_grid(inputs, padding=1, normalize=True),(1, 2, 0)));

print(f"Classes: {image_datasets['train'].classes}")
print(f"Class count: {image_datasets['train'].targets.count(0)}, {image_datasets['train'].targets.count(1)}, {image_datasets['train'].targets.count(2)}")
print(f"Samples:", len(image_datasets["train"]))
print(f"First sample: {image_datasets['train'].samples[0]}")
Classes: ['cat', 'dog', 'wild']
Class count: 50, 50, 50
Samples: 150
First sample: ('/Users/gtoti/Documents/GitHub/cpsc330-2024W1/lectures/data/animal_faces/train/cat/flickr_cat_000002.jpg', 0)
Now for each image in our dataset, we’ll extract a feature vector from a pre-trained model called densenet121, which is trained on the ImageNet dataset.
def get_features(model, train_loader, valid_loader):
"""Extract output of s model"""
with torch.no_grad(): # turn off computational graph stuff
Z_train = torch.empty((0, 1024)) # Initialize empty tensors
y_train = torch.empty((0))
Z_valid = torch.empty((0, 1024))
y_valid = torch.empty((0))
for X, y in train_loader:
Z_train = torch.cat((Z_train, model(X)), dim=0)
y_train = torch.cat((y_train, y))
for X, y in valid_loader:
Z_valid = torch.cat((Z_valid, model(X)), dim=0)
y_valid = torch.cat((y_valid, y))
return Z_train.detach(), y_train.detach(), Z_valid.detach(), y_valid.detach()
densenet = models.densenet121(weights="DenseNet121_Weights.IMAGENET1K_V1")
densenet.classifier = nn.Identity() # remove that last "classification" layer
Z_train, y_train, Z_valid, y_valid = get_features(
densenet, dataloaders["train"], dataloaders["valid"]
)
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Intel MKL WARNING: Support of Intel(R) Streaming SIMD Extensions 4.2 (Intel(R) SSE4.2) enabled only processors has been deprecated. Intel oneAPI Math Kernel Library 2025.0 will require Intel(R) Advanced Vector Extensions (Intel(R) AVX) instructions.
Now we have extracted feature vectors for all examples. What’s the shape of these features?
Z_train.shape
torch.Size([150, 1024])
The size of each feature vector is 1024 because the size of the last layer in densenet architecture is 1024.
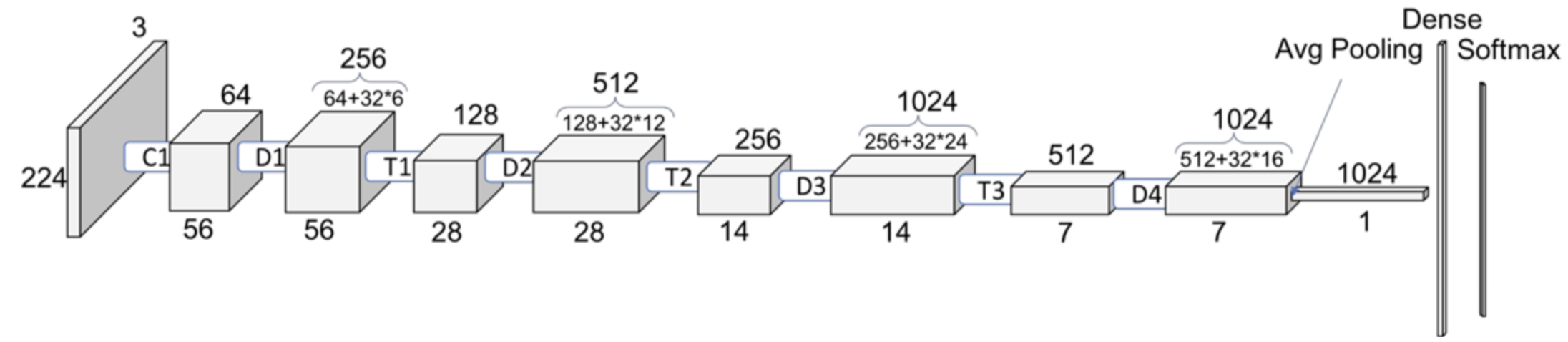
Source: https://towardsdatascience.com/understanding-and-visualizing-densenets-7f688092391a
Let’s examine the feature vectors.
pd.DataFrame(Z_train).head()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 1014 | 1015 | 1016 | 1017 | 1018 | 1019 | 1020 | 1021 | 1022 | 1023 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.000314 | 0.012780 | 0.001218 | 0.000419 | 0.149738 | 0.686221 | 0.000395 | 0.003002 | 0.259892 | 0.000367 | ... | 0.476957 | 0.363004 | 0.416335 | 0.009081 | 0.036484 | 0.175509 | 0.000000 | 0.162972 | 0.006990 | 1.557315 |
| 1 | 0.000394 | 0.003121 | 0.001451 | 0.000837 | 0.161817 | 0.740485 | 0.001043 | 0.001622 | 0.214080 | 0.000184 | ... | 0.269493 | 0.314986 | 0.167788 | 0.012516 | 0.548106 | 0.737186 | 2.771250 | 0.711778 | 0.922930 | 1.002003 |
| 2 | 0.000469 | 0.002094 | 0.003777 | 0.002629 | 0.056090 | 0.481665 | 0.000781 | 0.002938 | 0.306946 | 0.000349 | ... | 3.017158 | 1.015458 | 0.949892 | 1.303380 | 1.579836 | 1.437588 | 2.156760 | 2.159197 | 0.311045 | 2.631511 |
| 3 | 0.000407 | 0.001641 | 0.002493 | 0.002175 | 0.091890 | 0.209233 | 0.000441 | 0.003098 | 0.303395 | 0.000254 | ... | 1.573439 | 0.575524 | 0.588429 | 0.205897 | 0.039646 | 0.947311 | 0.869311 | 2.559459 | 2.240885 | 0.412880 |
| 4 | 0.000651 | 0.006221 | 0.002741 | 0.000561 | 0.111158 | 0.925524 | 0.000723 | 0.003589 | 0.297121 | 0.000553 | ... | 1.529008 | 0.433463 | 0.225723 | 0.342218 | 0.164489 | 0.038198 | 0.227794 | 0.607996 | 0.253003 | 5.604700 |
5 rows × 1024 columns
The features are hard to interpret but they have some important information about the images which can be useful for classification.
Let’s try out logistic regression on these extracted features.
pipe = make_pipeline(StandardScaler(), LogisticRegression(max_iter=2000))
pipe.fit(Z_train, y_train)
pipe.score(Z_train, y_train)
1.0
pipe.score(Z_valid, y_valid)
0.92
This is great accuracy for so little data (we only have 150 examples) and little effort of all different types of animals!!!
With logistic regression and flattened representation of images we got an accuracy of 0.66.
Object detection#
Another useful task and tool to know is object detection using YOLO (You Only Look Once) model.
Let’s identify objects in a sample image using a pretrained model called YOLO8.
List the objects present in this image.
Object detection using YOLO
Let’s try this out using a pre-trained model. We’ll use the ultralytics package for this, which you’ll have to install in the course environment.
pip install ultralytics
from ultralytics import YOLO
model = YOLO("yolov8n.pt") # pretrained YOLOv8n model
yolo_input = DATA_DIR + "yolo_test/3356700488_183566145b.jpg"
yolo_result = DATA_DIR + "yolo_result.jpg"
# Run batched inference on a list of images
result = model(yolo_input) # return a list of Results objects
result[0].save(filename=yolo_result)
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
# Load the images
input_img = mpimg.imread(yolo_input)
result_img = mpimg.imread(yolo_result)
# Create a figure to display the images side by side
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
# Display the first image
axes[0].imshow(input_img)
axes[0].axis('off') # Hide the axes
axes[0].set_title('Original Image')
# Display the second image
axes[1].imshow(result_img)
axes[1].axis('off') # Hide the axes
axes[1].set_title('Result Image')
# Show the images
plt.tight_layout()
plt.show()
Downloading https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt to 'yolov8n.pt'...
100%|██████████| 6.25M/6.25M [00:00<00:00, 16.6MB/s]
/Users/gtoti/opt/anaconda3/envs/cpsc330-24/lib/python3.12/site-packages/ultralytics/utils/torch_utils.py:219: UserWarning: Cannot set number of intraop threads after parallel work has started or after set_num_threads call when using native parallel backend (Triggered internally at /Users/runner/work/_temp/anaconda/conda-bld/pytorch_1711403213615/work/aten/src/ATen/ParallelNative.cpp:228.)
torch.set_num_threads(NUM_THREADS) # reset OMP_NUM_THREADS for cpu training
image 1/1 /Users/gtoti/Documents/GitHub/cpsc330-2024W1/lectures/data/yolo_test/3356700488_183566145b.jpg: 512x640 4 persons, 2 cars, 1 stop sign, 341.3ms
Speed: 7.9ms preprocess, 341.3ms inference, 20.0ms postprocess per image at shape (1, 3, 512, 640)
[W NNPACK.cpp:64] Could not initialize NNPACK! Reason: Unsupported hardware.

Summary#
Multi-class classification
Multi-class classification refers to classification with >2 classes.
Most sklearn classifiers work out of the box.
With
LogisticRegressionthe situation with the coefficients is a bit different, we get 1 coefficient per feature per class.
Neural networks
Neural networks are a flexible class of models.
They can be challenging to train and often require significant computational resources.; a lot more on that in CPSC 340.
They generally require leaving the sklearn ecosystem to tensorflow or pytorch.
They are particular powerful for structured input like images, videos, audio, etc.
The good news is we can use pre-trained neural networks.
This saves us a huge amount of time/cost/effort/resources.
We can use these pre-trained networks directly or use them as feature transformers.
Random cool stuff
Check out 3Blue1Brown series on Deep Learning.
A nice video which gives a high-level introduction to computer vision.
Style transfer: given a “content image” and a “style image”, create a new image with the content of one and the style of the other.
Here is the original paper from 2015, see Figure 2.
Here are more in this 2016 paper; see, e.g. Figures 1 and 7.
This has been done for video as well; see this video from 2016.
Image captioning: Transfer learning with NLP and vision
Colourization: see this 2016 project.
Inceptionism: let the neural network “make things up”
“Deep dream” video from 2015.