
Lecture 18: Fundamentals of Large Language Models¶
UBC 2025-26
Learning outcomes¶
From this lecture, students are expected to be able to:
Explain simple Markov Models for language applications and next-token prediction.
Explain how Large Language Models represent text.
Broadly explain the self-attention mechanism and its benefits.
Explain the role of Query, Key and Value vectors and weight matrices.
List potential harms of LLMs.
Introduction to large language models¶
Language models activity¶
Let’s start with a game!
Some of you will receive a sticky note with a word on it. Here’s what to do:
Look at your word. Don’t show it to anyone!
Think quickly: what word might logically follow this one?
✍️ Write your predicted next word on a new sticky note.You have 20 seconds. Trust your instincts.
Pass your predicted word to the person next to you (not the one you received).
Continue until the last person in your row has written their word.
You’ve just created a simple Markov model of language — each person predicted the next word based only on limited context.
“I saw the word data I wrote science.”
“I saw the word machine I wrote learning.”
This is how early language models worked: predict the next word using local context and co-occurrence probabilities.
Language model¶
A language model computes the probability distribution over sequences (of words or characters). Intuitively, this probability tells us how “good” or plausible a sequence of words is.

Check out this recent BMO ad.
import IPython
url = "https://2.bp.blogspot.com/-KlBuhzV_oFw/WvxP_OAkJ1I/AAAAAAAACu0/T0F6lFZl-2QpS0O7VBMhf8wkUPvnRaPIACLcBGAs/s1600/image2.gif"
IPython.display.IFrame(url, width=500, height=500)A simple model of language¶
Calculate the co-occurrence frequencies and probabilities based on these frequencies
Predict the next word based on these probabilities
This is a Markov model of language.
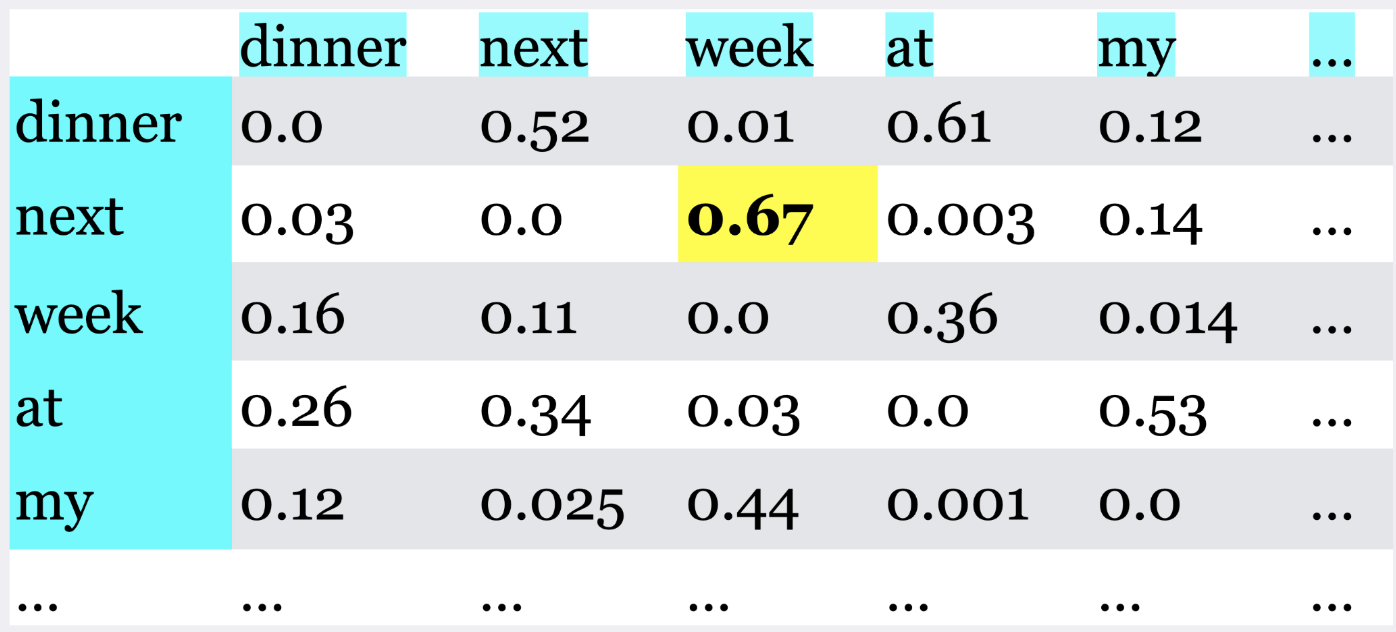
What are Large Language Models (LLMs)?¶
A Large Language Model (LLM) is a neural network trained to predict the next token in a sequence.
By doing this billions of times across massive text corpora, the model learns:
grammar and syntax
world knowledge
relationships between concepts
even reasoning patterns

Common architectures¶
| Decoder-only | Encoder-only | Encoder-decoder | |
|---|---|---|---|
| Examples | GPT-3, LLaMA, Gemini | BERT, RoBERTa | T5, BART |
| Uses | Text generation, chatbots | Text classification, embeddings | Translation, summarization |
| Context Handling | Considers earlier tokens | Bidirectional (full context) | Encodes input, generates output |
Most generative models you use (ChatGPT, Claude, Gemini) are decoder-only transformers.
Interim takeway: LLMs generate text by predicting the most likely token to follow a sequence.
We will now focus on gaining a basic understanding of the inner workings of a Large Language Model. To do so, we will use the material developed by Sebastian Raschka in his book Build a Large Language Model From Scratch.
All supplementary code for this book is available at https://

How do LLMs represent text?¶
LLMs work with text embeddings in high dimensional spaces. To make it understandable to the model, text is transformed through a process called tokenization. In its simplest form, tokenization means assigning to each word in a vocabulary a number.
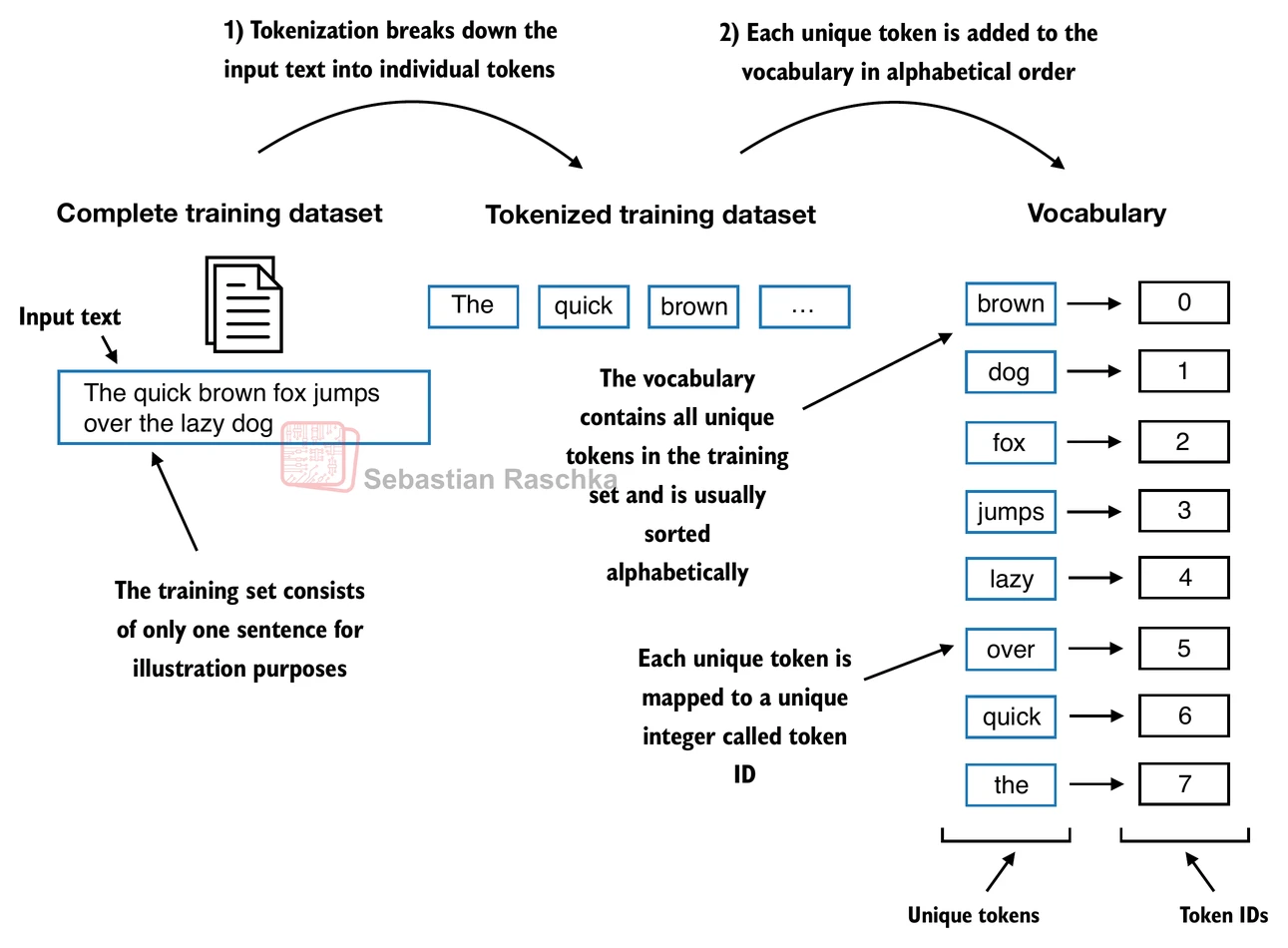
Let’s try tokenization using The Verdict by Edith Wharton, a public domain short story, as our vocabulary.
import os
import requests
# Import The Verdict if not already in the data folder
if not os.path.exists("../data/the-verdict.txt"):
url = (
"https://raw.githubusercontent.com/rasbt/"
"LLMs-from-scratch/main/ch02/01_main-chapter-code/"
"the-verdict.txt"
)
file_path = "../data/the-verdict.txt"
response = requests.get(url, timeout=30)
response.raise_for_status()
with open(file_path, "wb") as f:
f.write(response.content)with open("../data/the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
print("Total number of character:", len(raw_text))
print(raw_text[:99])Total number of character: 20479
I HAD always thought Jack Gisburn rather a cheap genius--though a good fellow enough--so it was no
We can parse this text in individual tokens. This will yield 4690 tokens.
import re
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', raw_text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
print(preprocessed[:30])
print("Total number of individual tokens: " + str(len(preprocessed)))['I', 'HAD', 'always', 'thought', 'Jack', 'Gisburn', 'rather', 'a', 'cheap', 'genius', '--', 'though', 'a', 'good', 'fellow', 'enough', '--', 'so', 'it', 'was', 'no', 'great', 'surprise', 'to', 'me', 'to', 'hear', 'that', ',', 'in']
Total number of individual tokens: 4690
Is this a vocabulary?
This is not a vocabulary yet - we need to eliminate duplicates and sort it:
all_words = sorted(set(preprocessed))
vocab = {token:integer for integer,token in enumerate(all_words)}
print("Size of vocabulary: " + str(len(all_words)))
# First 50 entries in the vocabulary
for i, item in enumerate(vocab.items()):
print(item)
if i >= 50:
breakSize of vocabulary: 1130
('!', 0)
('"', 1)
("'", 2)
('(', 3)
(')', 4)
(',', 5)
('--', 6)
('.', 7)
(':', 8)
(';', 9)
('?', 10)
('A', 11)
('Ah', 12)
('Among', 13)
('And', 14)
('Are', 15)
('Arrt', 16)
('As', 17)
('At', 18)
('Be', 19)
('Begin', 20)
('Burlington', 21)
('But', 22)
('By', 23)
('Carlo', 24)
('Chicago', 25)
('Claude', 26)
('Come', 27)
('Croft', 28)
('Destroyed', 29)
('Devonshire', 30)
('Don', 31)
('Dubarry', 32)
('Emperors', 33)
('Florence', 34)
('For', 35)
('Gallery', 36)
('Gideon', 37)
('Gisburn', 38)
('Gisburns', 39)
('Grafton', 40)
('Greek', 41)
('Grindle', 42)
('Grindles', 43)
('HAD', 44)
('Had', 45)
('Hang', 46)
('Has', 47)
('He', 48)
('Her', 49)
('Hermia', 50)
The SimpleTokenizerV1 class will allow us to encode and decode text using the vocabulary we just created.
class SimpleTokenizerV1:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = {i:s for s,i in vocab.items()}
def encode(self, text):
preprocessed = re.split(r"([,.:;?_!\"()']|--|\s)", text)
preprocessed = [
item.strip() for item in preprocessed if item.strip()
]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
text = " ".join([self.int_to_str[i] for i in ids])
# Replace spaces before the specified punctuations
text = re.sub(r"\s+([,.?!\\\"()\\'])", r'\1', text)
return texttokenizer = SimpleTokenizerV1(vocab)
text = """"It's the last he painted, you know,"
Mrs. Gisburn said with pardonable pride."""
ids = tokenizer.encode(text)
print(ids)[1, 56, 2, 850, 988, 602, 533, 746, 5, 1126, 596, 5, 1, 67, 7, 38, 851, 1108, 754, 793, 7]
# From tokens back to text
tokenizer.decode(ids)'" It\' s the last he painted, you know," Mrs. Gisburn said with pardonable pride.'Handling unknown tokens¶
What happens if we try encoding a word that is not in the vocabulary?
tokenizer = SimpleTokenizerV1(vocab)
text = "Hello, do you like tea. Is this-- a test?"
tokenizer.encode(text)---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[9], line 5
1 tokenizer = SimpleTokenizerV1(vocab)
3 text = "Hello, do you like tea. Is this-- a test?"
----> 5 tokenizer.encode(text)
Cell In[6], line 12, in SimpleTokenizerV1.encode(self, text)
7 preprocessed = re.split(r"([,.:;?_!\"()']|--|\s)", text)
9 preprocessed = [
10 item.strip() for item in preprocessed if item.strip()
11 ]
---> 12 ids = [self.str_to_int[s] for s in preprocessed]
13 return ids
KeyError: 'Hello'This is clearly a problem!
BytePair encoding¶
GPT-2 uses BytePair encoding (BPE) as its tokenizer. In BPE, words are split into small segments or even individual characters. These small segments can be combined to form all words, including unknown ones.
The original BPE tokenizer can be found here: src/encoder.py
Here, we will try the BPE tokenizer from OpenAI’s open-source tiktoken library - much faster than the original.
# If missing, install tiktoken
# !pip install tiktoken
# Or run
# conda install-c conda-forge tiktoken
# in your terminal (make sure right cpsc330 environment is active)import importlib
import tiktoken
tokenizer = tiktoken.get_encoding("gpt2")
text = (
"Hello, do you like tea? In the sunlit terraces of someunknownPlace."
)
integers = tokenizer.encode(text)
print(integers)[15496, 11, 466, 345, 588, 8887, 30, 554, 262, 4252, 18250, 8812, 2114, 286, 617, 34680, 27271, 13]
We can see we are getting more tokens than before. Let’s test a few:
tokenizer.decode([11, 8812, 34680])', terrunknown'Decoding the whole sentence looks like this:
tokenizer.decode(integers)'Hello, do you like tea? In the sunlit terraces of someunknownPlace.'Great! Now we can tokenize everything! Does this mean we are ready to train a LLM?
Unfortunately, no. Token IDs are just dictionary indexes and contain zero semantic information. For example, ID 40 is not “close” to ID 41 in meaning, they just happen to be close to each other in alphabetical order in our dictionary.
We need to convert these IDs into something more meaningful --> like vector embeddings!
From tokens IDs to token embeddings¶
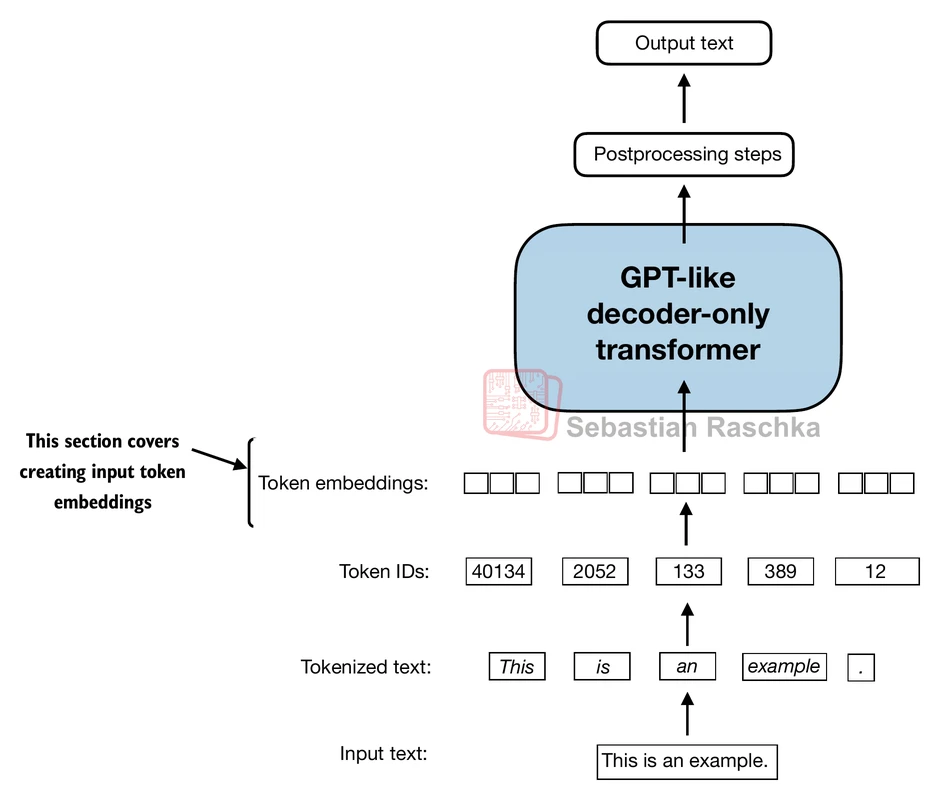
Vector embeddings, as we have seen in our previous class, can capture semantic relationships (close vectors have similar meanings). They also work very well with neural networks, the core architecture of every modern LLM (more on neural networks later).
As we have seen, text embeddings are typically high-dimensional, as more dimensions allow to better separate concepts and represent richer relationships between words. Vector dimensions for OpenAI’s GPT models vary depending on the model version, ranging from 768 for GPT-2 to over 12,000 dimensions for GPT-3 Davinci.
An interesting difference is that these embedding are part of the LLM itself and are updated (trained) during model training, unlike the classic static embeddings (Word2Vec, GloVe) we have seen before.
Here is a small example of what token embeddings would look like for a vocabulary of 6 words encoded in 3 dimensions:
import torch
vocab_size = 6
output_dim = 3
torch.manual_seed(123)
embedding_layer = torch.nn.Embedding(vocab_size, output_dim)
print(embedding_layer.weight)Parameter containing:
tensor([[ 0.3374, -0.1778, -0.1690],
[ 0.9178, 1.5810, 1.3010],
[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-1.1589, 0.3255, -0.6315],
[-2.8400, -0.7849, -1.4096]], requires_grad=True)
The first vector would be the token ID of index 0, the second vector the token ID of index 1, and so on.
18.1 Select all of the following statements which are True (iClicker)¶
(A) A 20 words sentence will be encoded using 20 token embeddings.
(B) Token IDs contain no semantic information.
(C) Higher vector dimensions allow to encode more complex and nouanced meaning.
(D) Vector embeddings are updated as the model is trained.
Now we know how a Large Language Model encodes text. From our first activity, we also got an intuition of how they work: given a token (or a sequence of tokens), the model will try to predict the one that comes next.
With words, that would look like this:

From Markov models to meaning¶
Markov models can predict short sequences, but they quickly fall apart with longer context.
For example:
“I am studying law at the University of British Columbia because I want to work as a ___”
To predict the last word (lawyer), we must remember information from the beginning of the sentence — something a simple Markov model can’t do.
We need models that can remember long-range dependencies and weigh context differently.
Self-attention mechanisms¶
Self-attention is the core mechanism behind modern LLMs like GPT. It allows each word (token) in a sentence to look at every other word and decide how much attention to pay to them.
This is what enables models to understand relationships like:
“The cat sat on the mat because it was tired.”
Self-attention helps the model understand that “it” refers to “the cat” — not “the mat”. It is an essential property if we hope to understand and generate long, coherent sentences.
The idea of attention and the architecture behind it (transformer) were first introduced in 2017 in the paper "Attention is all you need’. Since then, the paper has been cited more than 200,000 times!
Example of a simplified self-attention mechanism¶
To understand this idea, we will start by looking at a simplified self-attention mechanism. Please note that this is not the self-attention mechanism used in modern LLMs - we will describe that later.
Imagine I am working with a short sentence like “Your journey starts with one step”. Below you can see a possible embedding of this sentence using 3-dimensional vectors.
import torch
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts (x^3)
[0.22, 0.58, 0.33], # with (x^4)
[0.77, 0.25, 0.10], # one (x^5)
[0.05, 0.80, 0.55]] # step (x^6)
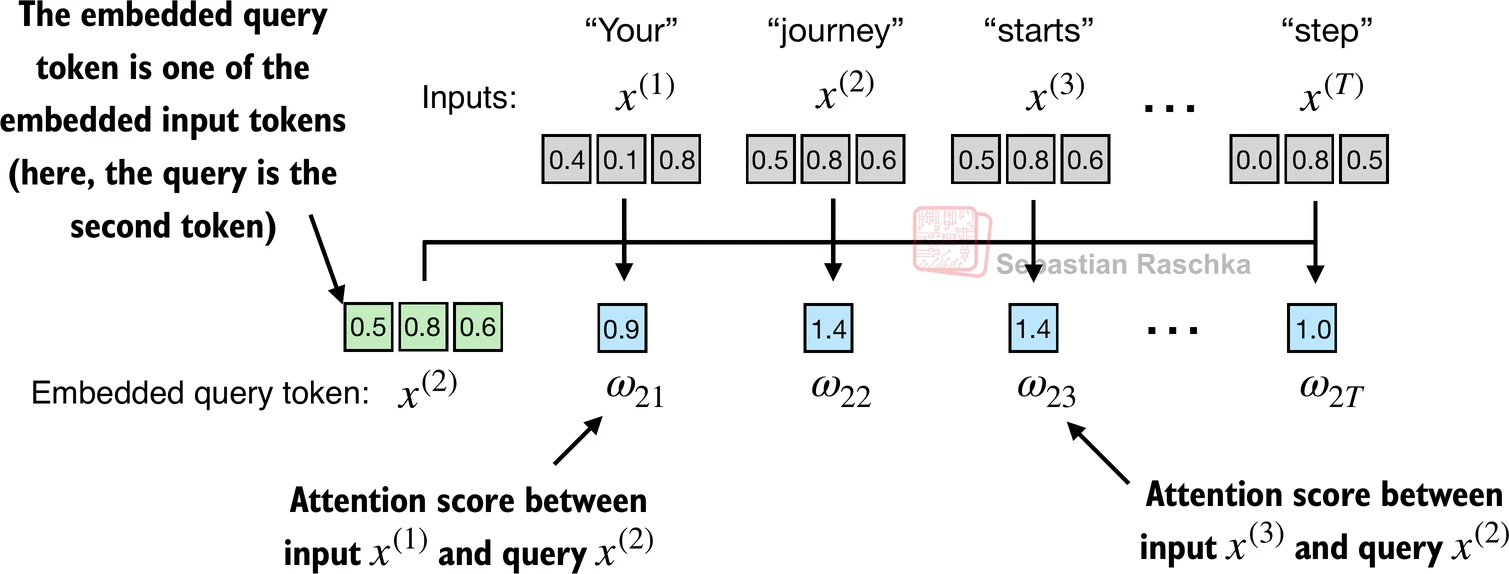
)I could start representing attention as similarity between vectors, using simple dot products.
Let’s use the word “journey”, for example: by computing the dot product between the word “journey” and every other word in the sentence, I could start seeing which words in the sentence are more similar to “journey”. We can call these similarities attention scores.
# These code shows that the attention scores visible in the figure are in fact the dot products
# between our query ("journey") and other words in the sentence.
import numpy as np
query = np.array([0.55, 0.87, 0.66]) # "journey"
v1 = np.array([0.43, 0.15, 0.89]) # "Your" - you may swap the vector to get different attention scores
np.dot(query, v1)0.9544If we looks at all the scores, we can see high similarity between the word “journey” and the words “start” and “step”, while the word “one” appears to be less similar.
query = inputs[1] # 2nd input token is the query
attn_scores = torch.empty(inputs.shape[0])
for i, x_i in enumerate(inputs):
attn_scores[i] = torch.dot(x_i, query) # dot product
print(attn_scores)tensor([0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865])
Scores are usually normalized so that the total attention adds to 1. A commonly used normalization strategy in this case is using the softmax function, which has some advantages during model training.
We call the normalized scores attention weights.
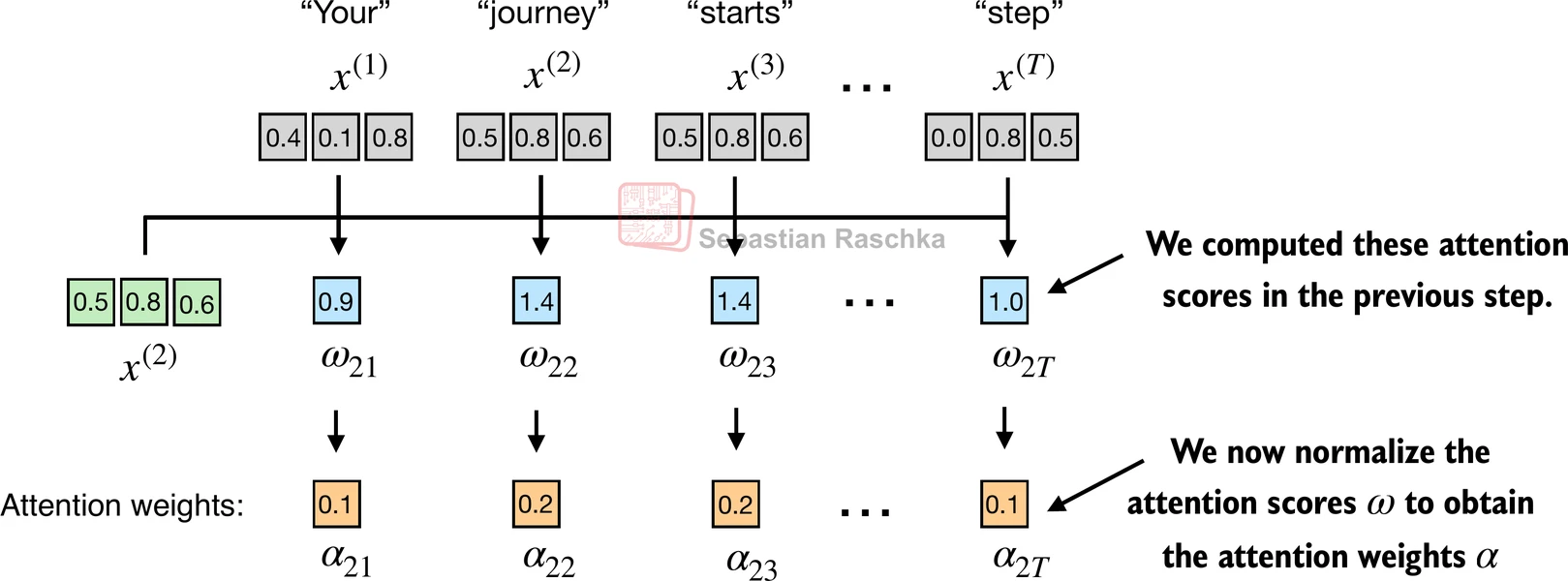
attn_weights = torch.softmax(attn_scores, dim=0)
print("Attention weights:", attn_weights)
print("Sum:", attn_weights.sum())Attention weights: tensor([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])
Sum: tensor(1.)
The last step in the chain is to multiply each vector in the sentence by its attention weight and add them all together. This operation gives us the context vector for our query word “journey”, the final summary this word buildt after looking at all the other words in the sentence and estimating which ones are more relevant.
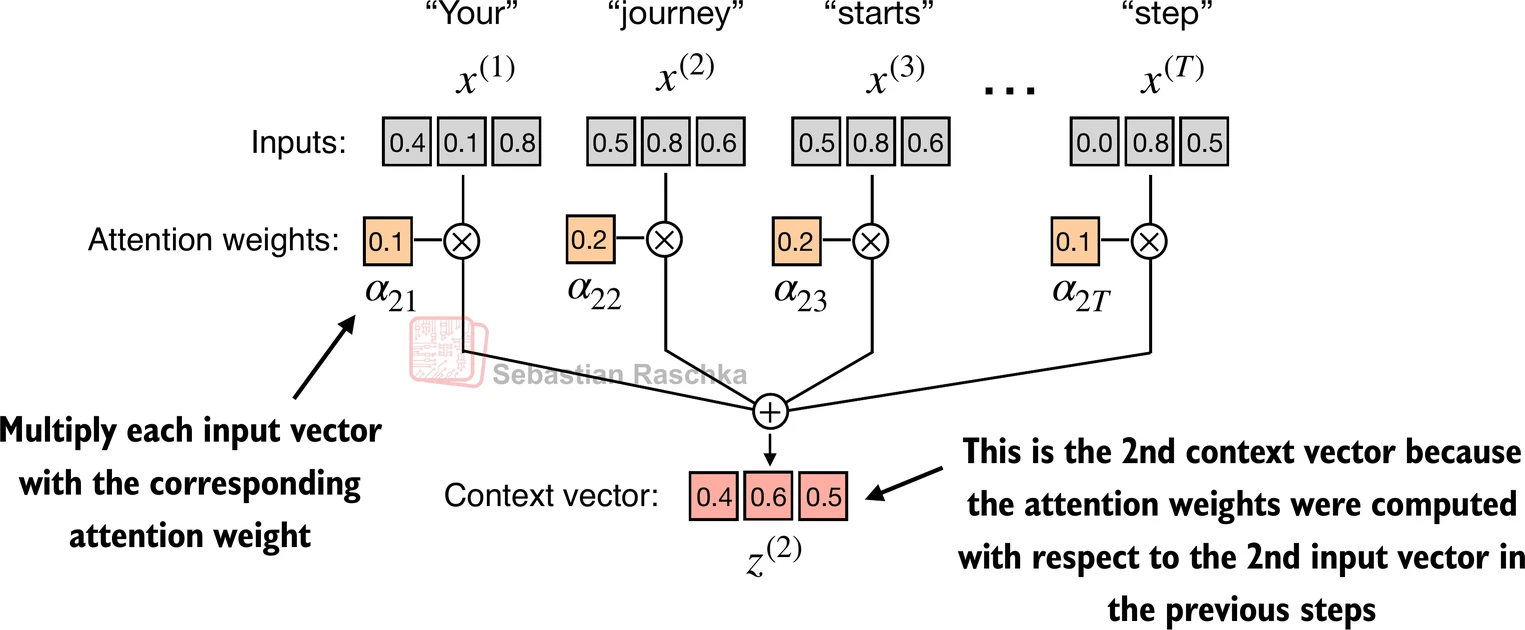
A context vector helps making sense of words in their context and resolving ambiguities. It could be the difference between intepreting the word “bank” as “river bank” or “financial bank”.
# Context vector for "journey"
query = inputs[1] # 2nd input token is the query
context_vec_2 = torch.zeros(query.shape)
for i,x_i in enumerate(inputs):
context_vec_2 += attn_weights[i]*x_i
print(context_vec_2)tensor([0.4419, 0.6515, 0.5683])
In real LLMs, things get even more complex!
The simple attention mechanism we saw in our example is not sophisticated enough. Modern LLMs actually compute three vectors for each token:
Query (Q) → A vector encoding what the token is looking for - for example, a token could be interested in knowing if any edjectives precede it.
Key (K) → A vector encoding the potential answer to the query.
Value (V) → A vector encoding how to move from the query to the query answer.
For every word, the attention is
Words that correctly answer the query will receive a high attention value, while unrelated words will receive a small one.
Example¶
The blue bird was basking in the warm sun.
Let’s say that “sun” is the query, and it’s looking for preceding adjectives --> the vector Q is computed
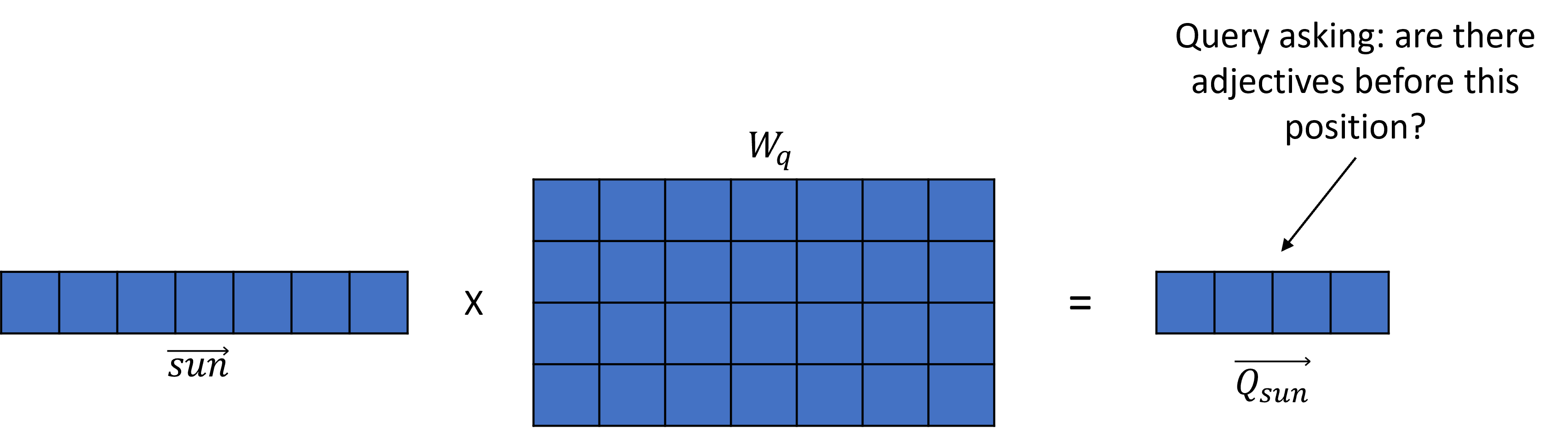
Notice the smaller size of the query vector.
Example¶
The blue bird was basking in the warm sun.
For every other word, a key vector K is produced, answering the question “are you an adjective”?
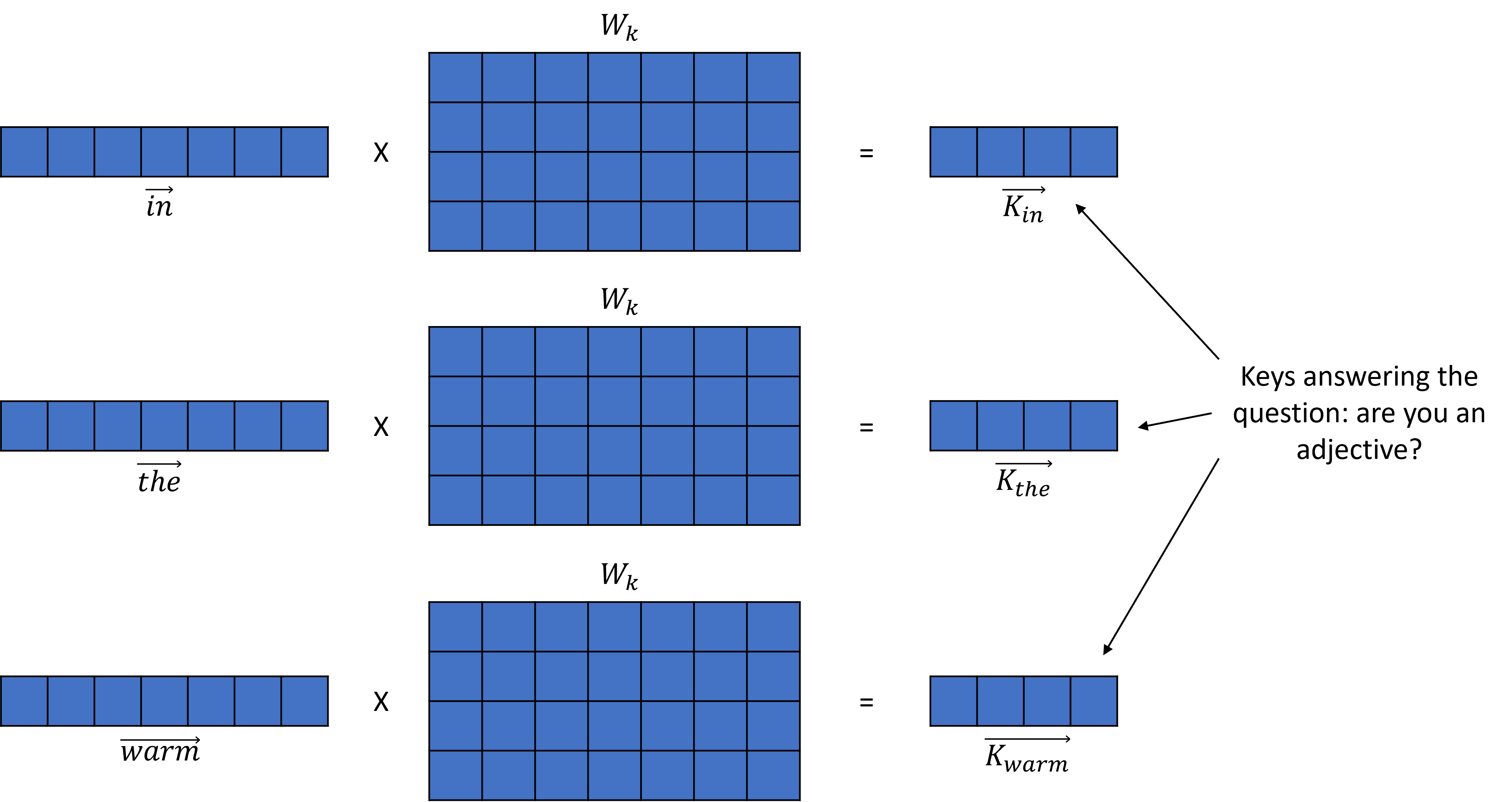
(Not all words included in the picture because of space limit)
Example¶
The blue bird was basking in the warm sun.
The dot product is computed between Q and each vector K: if the value is high, it means the query and the answer match; in our case, we would expect to see high values between “sun” and “warm”, and low values for the others (even “blue” - although it is an adjective, a well trained LLM will know that this word is rarely associated with “sun”)
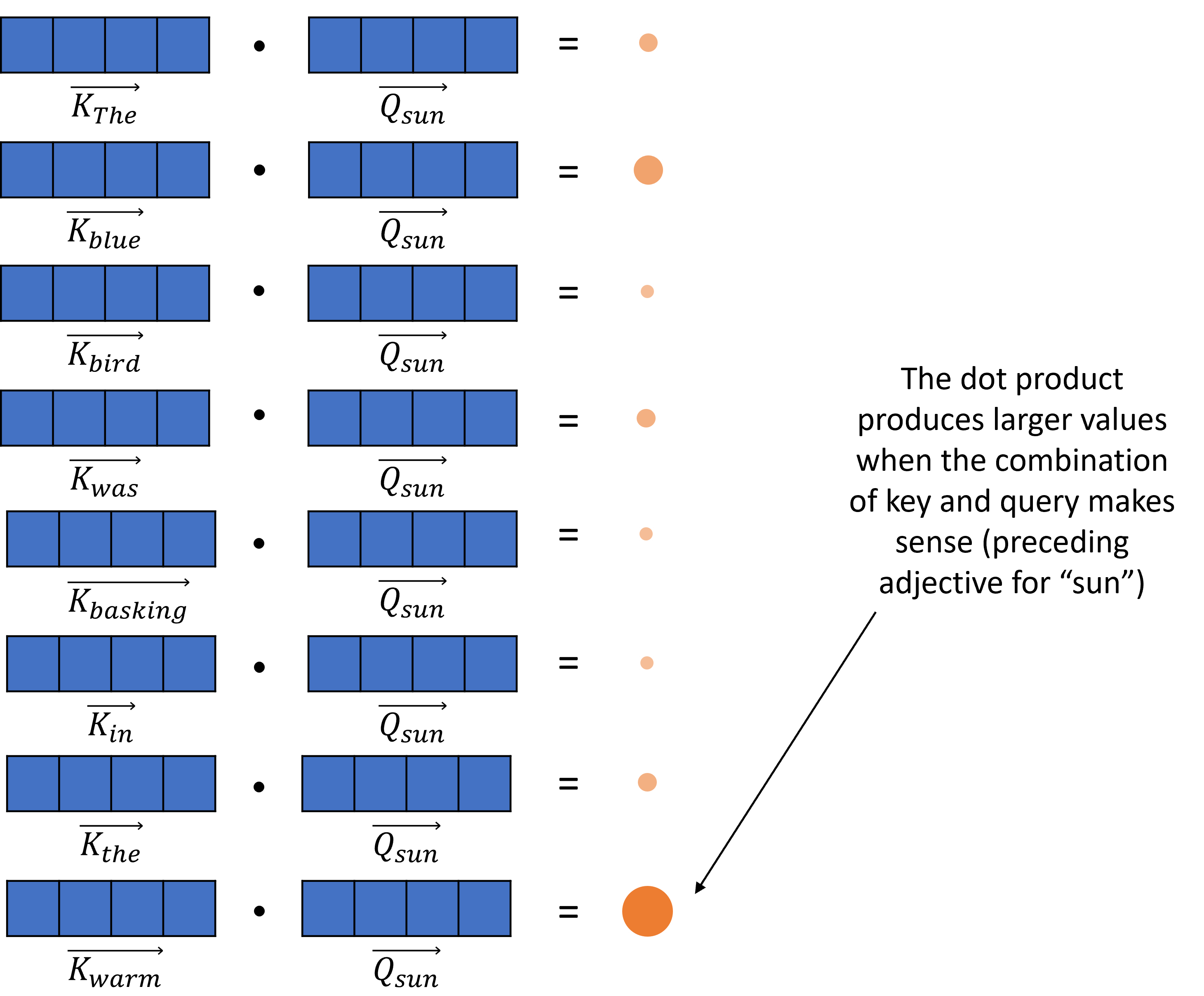
The remaining operations (scaling, multiplying by the value vector) help us move in the embedding space toward the area associated with the idea of “warm sun” and give us the final attention value.
Question: Where do Q, K and V come from?
In order to get to a token embedding to the corresponding Q, K and V vectors, we multiply them by weight matrixes .
The matrixes size corresponds to the embedding dimension x the number of features the model uses to express the comparison it is trying to make.
More token embedding dimensions translate to more meaningful individual tokens
A higher value of features allow to represent richer relationships
GPT-3 uses a size of 12,288 for its token embeddings, and 128 features to represent relationships. That is the size of query and key vectors.
This also means that include 1,572,864 parameters each, which are learned during the model training.
But wait - we said that is used to represent a particular query (e.g. looking for preceding adjectives), and is used to calculate the possible answers to that query - does that mean that there are multiple versions of and ?
Thats exactly right!
GPT-3 has 96 attention heads, each dedicated to the analysis of a particular relationship. Each head has its version of , which needs to be learned.
And, this operation is actually carried out across 96 different layers, which have 96 attention heads each.
This adds up to more than 43 billions parameters to learn - and that’s not even the complete architecture. The final number is closer to 175 billion parameters.
For a more in-depth explanation about attention and transformers, I highly recommend this video.
OK - now we have a massive model able to generate next token predictions, and it is very sophisticated and coherent thanks to the self-attention mechanism. Is this the model that I chat with when I use ChatGPT, Claude, etc?
Not quite...

Next token prediction is surprisingly powerful. Because they are trained on huge amounts of human reasoning, models can learn:
language
knowledge
reasoning structures
problem-solving patterns
So much that Ilya Sutskever, the co-founder of OpenAI, has frequently argued that it would be a sufficient objective for developing Artificial General Intelligence (AGI).
Reasoning as a compression strategy¶
LLMs cannot memorize all text they sees. Instead, it must compress patterns in the data.
Generally speaking, the best compression of reasoning-heavy text is to learn general rules like:
arithmetic rules
grammar
logical structure
causal relationships
For example, instead of memorizing:
12 + 7 = 19
13 + 7 = 20
14 + 7 = 21It is more efficient to learn the algorithm of addition. The newest, largest models are particularly good at this.
However, models that have been trained only for next-token prediction, may be a bit unpredictable and unrefined when engaging in question answering.
For example, they may continue the pattern rather than just answering the question:
User Question:
What is the capital of France?Model Answer:
Paris.
What is the capital of Germany?
Berlin.
...Fine-tuning makes models more usable¶
A second training phase refines and aligns the model’s behavior. It typically includes:
Instruction Tuning¶
Training on curated instruction-following datasets
Teaching the model to follow specific formats and be more helpful
RLHF (Reinforcement Learning from Human Feedback)¶
Aligning responses with human preferences
Making outputs more accurate, safe, and useful
Reducing harmful or unhelpful responses
Warning: an implication of this is that undesirable behaviours are often hidden, but not fully removed, from the model.
More on this in the tutorial!
18.2 Select all of the following statements which are True (iClicker)¶
(A) One of the dimensions of the weight matrix must match the size of the token embedding, but the other may vary, with larger dimensions leading to richer representations.
(B) Next-token predictors memorize large amounts of text.
(C) The attention mechanism allows to resolve ambiguities and make sense of longer sentences.
(D) Attention(Q, K, V) is a scalar.
NLP pipelines before and after LLMs¶
| Traditional NLP Pipeline | LLM-Powered Pipeline |
|---|---|
| Text preprocessing, tokenization | Minimal preprocessing |
| Feature extraction (BoW, TF-IDF, embeddings) | Implicit contextual embeddings |
| One model per task | One model, many tasks |
| Needs labeled data | Zero-shot and few-shot learning |
LLMs have shifted NLP from feature engineering to prompt engineering.
There are many Python libraries that make it easy to use pretrained LLMs:
🤗 Transformers — unified interface for hundreds of models
OpenAI API — GPT-3.5 / GPT-4 models
LangChain — building complex LLM workflows
Haystack — retrieval-augmented generation (RAG)
spaCy Transformers — NLP with transformer backends engineering**.
Example: Sentiment analysis using a pretrained model¶
from transformers import pipeline, AutoModelForTokenClassification, AutoTokenizer
# Sentiment analysis pipeline
analyzer = pipeline("sentiment-analysis", model='distilbert-base-uncased-finetuned-sst-2-english')
analyzer(["I asked my model to predict my future, and it said '404: Life not found.'",
'''Machine learning is just like cooking—sometimes you follow the recipe,
and other times you just hope for the best!.'''])Device set to use cpu
[{'label': 'NEGATIVE', 'score': 0.995707631111145},
{'label': 'POSITIVE', 'score': 0.9994770884513855}]Now let’s try emotion classification
from datasets import load_dataset
dataset = load_dataset("dair-ai/emotion")
exs = dataset["test"]["text"][3:15]
exs['i left with my bouquet of red and yellow tulips under my arm feeling slightly more optimistic than when i arrived',
'i was feeling a little vain when i did this one',
'i cant walk into a shop anywhere where i do not feel uncomfortable',
'i felt anger when at the end of a telephone call',
'i explain why i clung to a relationship with a boy who was in many ways immature and uncommitted despite the excitement i should have been feeling for getting accepted into the masters program at the university of virginia',
'i like to have the same breathless feeling as a reader eager to see what will happen next',
'i jest i feel grumpy tired and pre menstrual which i probably am but then again its only been a week and im about as fit as a walrus on vacation for the summer',
'i don t feel particularly agitated',
'i feel beautifully emotional knowing that these women of whom i knew just a handful were holding me and my baba on our journey',
'i pay attention it deepens into a feeling of being invaded and helpless',
'i just feel extremely comfortable with the group of people that i dont even need to hide myself',
'i find myself in the odd position of feeling supportive of']from transformers import AutoTokenizer
from transformers import pipeline
import torch
#Load the pretrained model
model_name = "facebook/bart-large-mnli"
classifier = pipeline('zero-shot-classification', model=model_name)
exs = dataset["test"]["text"][:10]
candidate_labels = ["sadness", "joy", "love","anger", "fear", "surprise"]
outputs = classifier(exs, candidate_labels)Device set to use cpu
import pandas as pd
pd.DataFrame(outputs)Harms of large language models
While these models are super powerful and useful, be mindful of the harms caused by these models. Some of the harms as summarized [here]:
performance disparties
social biases and stereotypes
toxicity
misinformation
security and privacy risks
copyright and legal protections
environmental impact
centralization of power
For more, see Stanford CS324 Lecture on Harms of LLMs.
18.3 iClicker¶
After learning about how LLM works, do you think it is improper to use words like “thinking” and “understanding” when talking about what these models do?
(A) Strongly Disagree
(B) Disagree
(C) Unsure/Neutral
(D) Agree
(E) Strongly Agree
Takeaway message
Language modeling began as simple next-word prediction.
Transformers introduced self-attention for contextual understanding.
LLMs scaled these ideas to billions of parameters, enabling reasoning and generation.
With great power comes great responsibility — awareness and ethical use are key.