
Lecture 1: Course Introduction¶
UBC 2025-26
Imports¶
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
import sys
sys.path.append(os.path.join(os.path.abspath(".."), "code"))
from IPython.display import HTML, display
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
plt.rcParams["font.size"] = 16
pd.set_option("display.max_colwidth", 200)
%matplotlib inline
DATA_DIR = '../data/' Learning outcomes¶
From this lecture, you will be able to
Explain the difference between AI, ML, and DL
Describe what machine learning is and when it is appropriate to use ML-based solutions.
Briefly describe supervised learning.
Differentiate between traditional programming and machine learning.
Evaluate whether a machine learning solution is suitable for your problem or whether a rule-based or human-expert solution is more appropriate.
Characters in this course?¶
CPSC 330 teaching team (instructors and the TAs)
Eva (a fictitious enthusiastic student)
And you all, of course 🙂!
Meet Eva (a fictitious persona)!¶

Eva is among one of you. She has some experience in Python programming. She knows machine learning as a buzz word. During her recent internship, she has developed some interest and curiosity in the field. She wants to learn what is it and how to use it. She is a curious person and usually has a lot of questions!
What are AI, ML, and DL?¶
Before we dive in, let’s clear up the difference between these buzzwords you’ve probably heard: AI, ML, and DL.
Artificial Intelligence (AI): Broad goal of making computers perform tasks that typically require human intelligence (e.g., chess-playing programs, virtual assistants)
Machine Learning (ML): A subset of AI where systems learn patterns from data instead of being explicitly programmed (e.g., spam filtering, predicting housing prices)
Deep Learning (DL): A subset of ML that uses multi-layered neural networks to learn complex patterns (e.g., image classification, speech-to-text)

In this course, we’ll focus on machine learning, the practical, everyday workhorse of AI. Toward the end, you’ll also get a high-level overview of deep learning, the driver behind recent breakthroughs in generative AI.
Saving time and scaling products¶
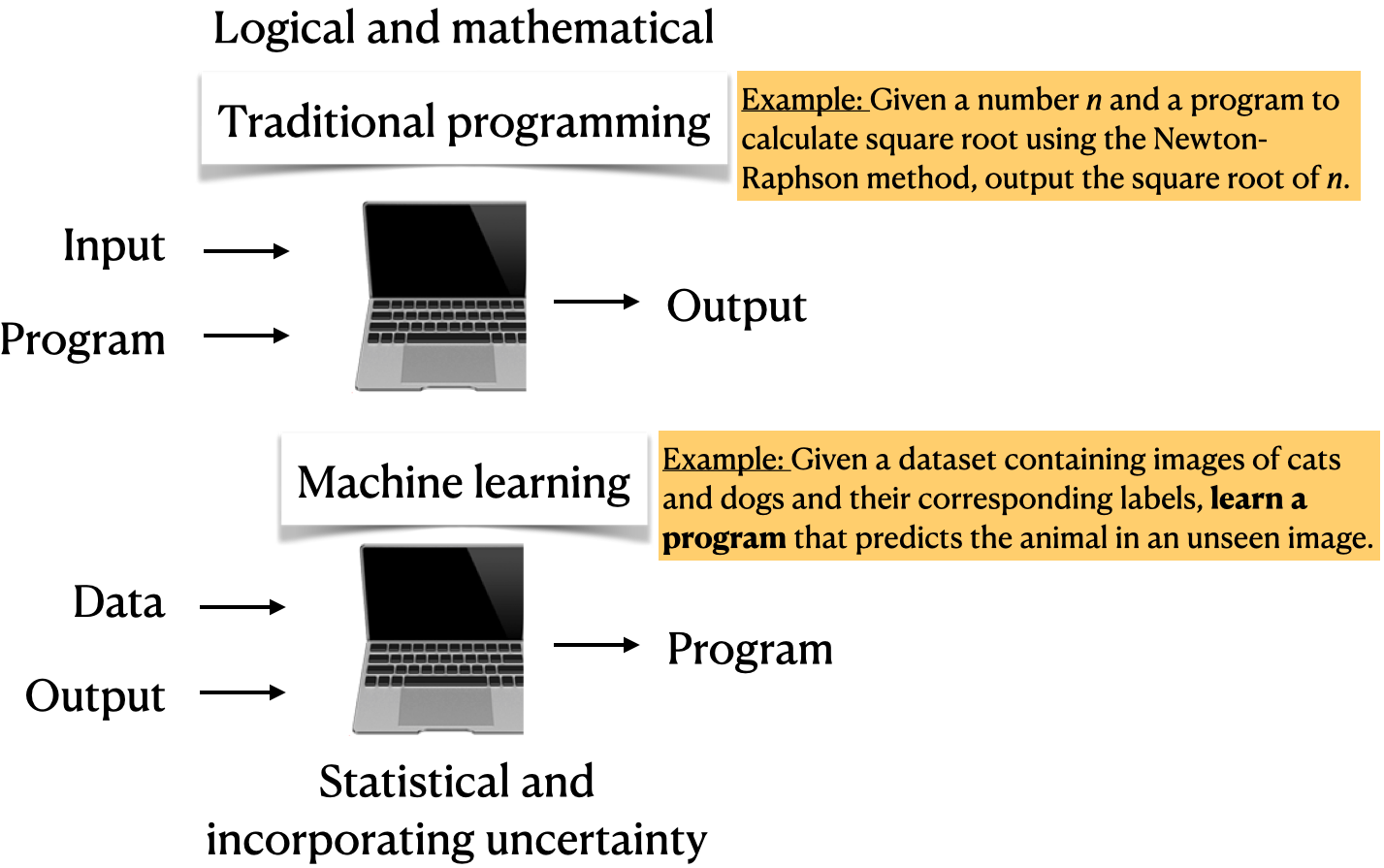
Imagine writing a program for spam identification, i.e., whether an email is spam or non-spam.
Traditional programming
Come up with rules using human understanding of spam messages.
Time consuming and hard to come up with robust set of rules.
Machine learning
Collect large amount of data of spam and non-spam emails and let the machine learning algorithm figure out rules.
With machine learning, you’re likely to
Save time
Customize and scale products
Supervised machine learning¶
Types of machine learning¶
Here are some typical learning problems.
Supervised learning (Gmail spam filtering)
Training a model from input-output pairs (features and labeled targets) to make predictions on unseen data.
Unsupervised learning (Google News)
Training a model to discover hidden structure or patterns in unlabeled data (e.g., clustering, dimensionality reduction)
Reinforcement learning (AlphaGo)
A family of algorithms for finding suitable actions to take in a given situation in order to maximize a long-term reward.
Generative AI (ChatGPT)
Training a model to generate new data resembling the training data (e.g., text, images, music). Modern generative AI systems often combine supervised, unsupervised, and reinforcement learning techniques.
Recommendation systems (Amazon item recommendation system)
Predict user ratings or preferences for items.
Typically combines supervised learning and unsupervised learning.
What is supervised machine learning (ML)?¶
Training data comprises a set of observations () and their corresponding targets ().
We wish to find a model function that relates to .
We use the model function to predict targets of new examples.
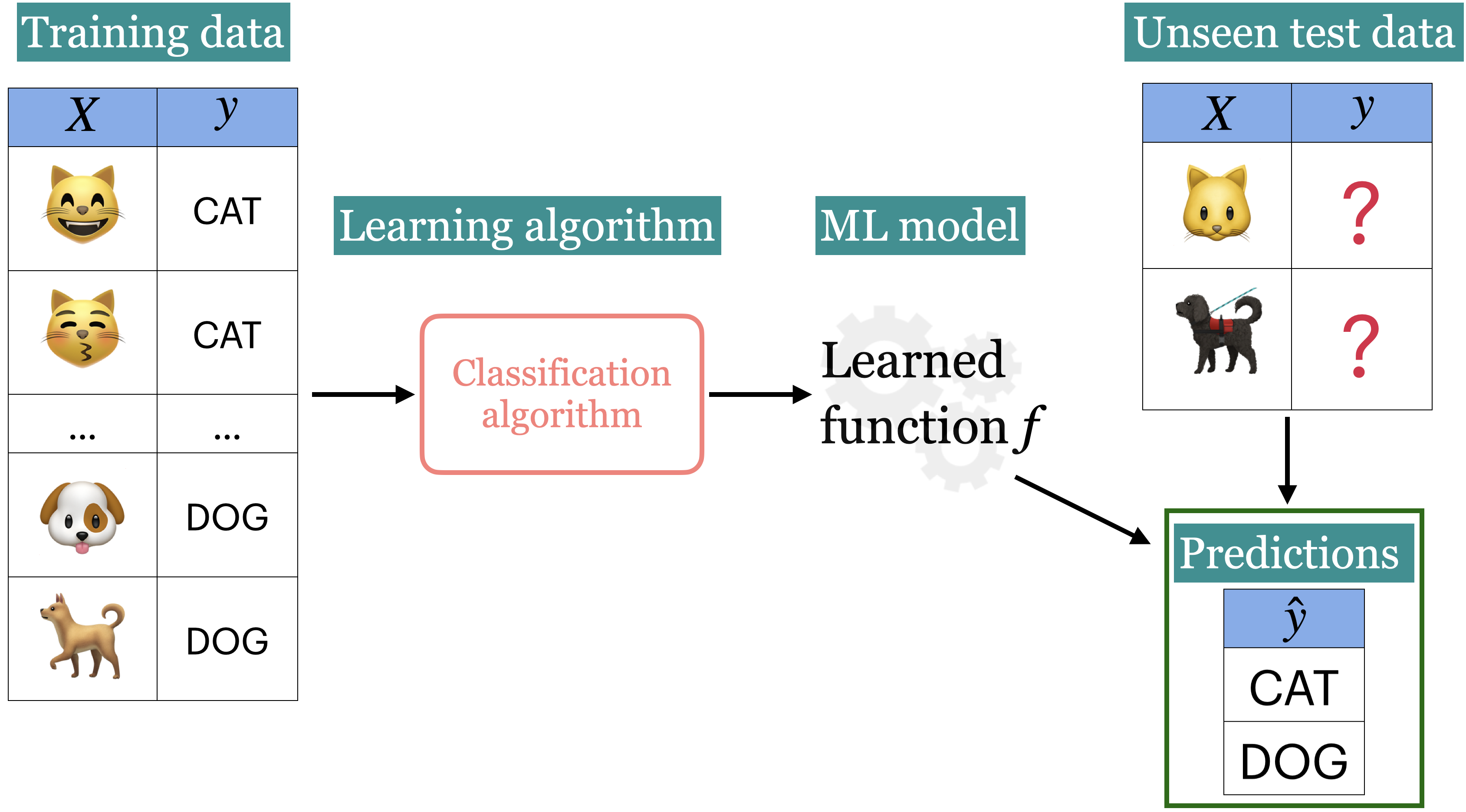
Example: Predict whether a message is spam or not¶
Input features and target ¶
Training a supervised machine learning model with and ¶
Source
sms_df = pd.read_csv(DATA_DIR + "spam.csv", encoding="latin-1")
sms_df = sms_df.drop(columns = ["Unnamed: 2", "Unnamed: 3", "Unnamed: 4"])
sms_df = sms_df.rename(columns={"v1": "target", "v2": "sms"})
train_df, test_df = train_test_split(sms_df, test_size=0.10, random_state=42)
HTML(train_df.head().to_html(index=False))X_train, y_train = train_df["sms"], train_df["target"]
X_test, y_test = test_df["sms"], test_df["target"]
clf = make_pipeline(CountVectorizer(max_features=5000), LogisticRegression(max_iter=5000))
clf.fit(X_train, y_train);Predicting on unseen data using the trained model¶
pd.DataFrame(X_test[0:4])pred_dict = {
"sms": X_test[0:4],
"spam_predictions": clf.predict(X_test[0:4]),
}
pred_df = pd.DataFrame(pred_dict)
pred_df.style.set_properties(**{"text-align": "left"})We have accurately predicted labels for the unseen text messages above!
(Supervised) machine learning: popular definition¶
A field of study that gives computers the ability to learn without being explicitly programmed.
Arthur Samuel (1959)
ML is a different way to think about problem solving.
Examples¶
Let’s look at some concrete examples of supervised machine learning.
Example 1: Predicting whether a patient has a liver disease or not¶
Input data¶
Suppose we are interested in predicting whether a patient has the disease or not. We are given some tabular data with inputs and outputs of liver patients, as shown below. The data contains a number of input features and a special column called “Target” which is the output we are interested in predicting.
Source
df = pd.read_csv(DATA_DIR + "indian_liver_patient.csv")
df = df.drop(columns = ["Gender"])
df["Dataset"] = df["Dataset"].replace(1, "Disease")
df["Dataset"] = df["Dataset"].replace(2, "No Disease")
df.rename(columns={"Dataset": "Target"}, inplace=True)
train_df, test_df = train_test_split(df, test_size=4, random_state=42)
HTML(train_df.head().to_html(index=False))Building a supervise machine learning model¶
Let’s train a supervised machine learning model with the input and output above.
from lightgbm.sklearn import LGBMClassifier
X_train = train_df.drop(columns=["Target"])
y_train = train_df["Target"]
X_test = test_df.drop(columns=["Target"])
y_test = test_df["Target"]
model = LGBMClassifier(random_state=123, verbose=-1)
model.fit(X_train, y_train)Model predictions on unseen data¶
Given features of new patients below we’ll use this model to predict whether these patients have the liver disease or not.
HTML(X_test.reset_index(drop=True).to_html(index=False))pred_df = pd.DataFrame({"Predicted_target": model.predict(X_test).tolist()})
df_concat = pd.concat([pred_df, X_test.reset_index(drop=True)], axis=1)
HTML(df_concat.to_html(index=False))Example 2: Predicting the label of a given image¶
Suppose you want to predict the label of a given image using supervised machine learning. We are using a pre-trained model here to predict labels of new unseen images.
import img_classify
from PIL import Image
import glob
import matplotlib.pyplot as plt
# Predict topn labels and their associated probabilities for unseen images
images = glob.glob(DATA_DIR + "test_images/*.*")
class_labels_file = DATA_DIR + 'imagenet_classes.txt'
for img_path in images:
img = Image.open(img_path).convert('RGB')
img.load()
plt.imshow(img)
plt.show();
df = img_classify.classify_image(img_path, class_labels_file)
print(df.to_string(index=False))
print("--------------------------------------------------------------")
Class Probability score
tiger cat 0.636
tabby, tabby cat 0.174
Pembroke, Pembroke Welsh corgi 0.081
lynx, catamount 0.011
--------------------------------------------------------------
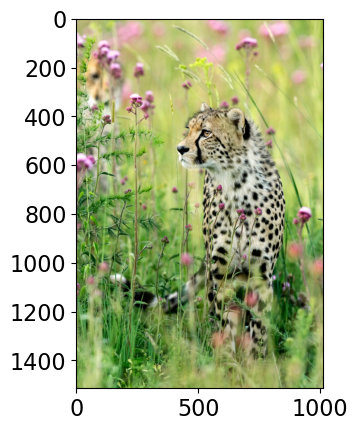
Class Probability score
cheetah, chetah, Acinonyx jubatus 0.994
leopard, Panthera pardus 0.005
jaguar, panther, Panthera onca, Felis onca 0.001
snow leopard, ounce, Panthera uncia 0.000
--------------------------------------------------------------

Class Probability score
macaque 0.885
patas, hussar monkey, Erythrocebus patas 0.062
proboscis monkey, Nasalis larvatus 0.015
titi, titi monkey 0.010
--------------------------------------------------------------
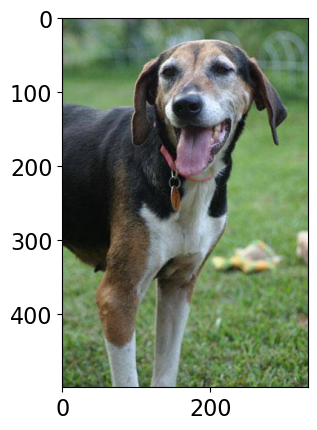
Class Probability score
Walker hound, Walker foxhound 0.582
English foxhound 0.144
beagle 0.068
EntleBucher 0.059
--------------------------------------------------------------
Example 3: Predicting sentiment expressed in a movie review¶
Suppose you are interested in predicting whether a given movie review is positive or negative. You can do it using supervised machine learning.
imdb_df = pd.read_csv(DATA_DIR + "imdb_master.csv", encoding="ISO-8859-1")
imdb_df['sentiment'].value_counts()sentiment
positive 25000
negative 25000
Name: count, dtype: int64Source
imdb_df = pd.read_csv(DATA_DIR + "imdb_master.csv", encoding="ISO-8859-1")
train_df, test_df = train_test_split(imdb_df, test_size=0.10, random_state=123)
HTML(train_df.head().to_html(index=False))# Build an ML model
X_train, y_train = train_df["review"], train_df["sentiment"]
X_test, y_test = test_df["review"], test_df["sentiment"]
clf = make_pipeline(CountVectorizer(max_features=5000), LogisticRegression(max_iter=5000))
clf.fit(X_train, y_train);# Predict on unseen data using the built model
pred_dict = {
"reviews": X_test[0:4],
"sentiment_predictions": clf.predict(X_test[0:4]),
}
pred_df = pd.DataFrame(pred_dict)
pred_df.style.set_properties(**{"text-align": "left"})Example 4: Predicting housing prices¶
Suppose we want to predict housing prices given a number of attributes associated with houses.
Source
df = pd.read_csv( DATA_DIR + "kc_house_data.csv")
df = df.drop(columns = ["id", "date"])
df.rename(columns={"price": "target"}, inplace=True)
train_df, test_df = train_test_split(df, test_size=0.2, random_state=4)
HTML(train_df.head().to_html(index=False))# Build a regression model
from lightgbm.sklearn import LGBMRegressor
X_train, y_train = train_df.drop(columns= ["target"]), train_df["target"]
X_test, y_test = test_df.drop(columns= ["target"]), train_df["target"]
model = LGBMRegressor()
#model = XGBRegressor()
model.fit(X_train, y_train);# Predict on unseen examples using the built model
pred_df = pd.DataFrame(
# {"Predicted target": model.predict(X_test[0:4]).tolist(), "Actual price": y_test[0:4].tolist()}
{"Predicted_target": model.predict(X_test[0:4]).tolist()}
)
df_concat = pd.concat([pred_df, X_test[0:4].reset_index(drop=True)], axis=1)
HTML(df_concat.to_html(index=False))To summarize, supervised machine learning can be applied to many problems and types of data, but remember that it’s not always the right tool.
Use machine learning when you have a large, complex dataset and the decision rules are unknown, fuzzy, or too complicated to define explicitly.
Pause before jumping in: ML is exciting, but always ask whether you really need it for your problem.
Use rule-based systems when the logic is clear, deterministic, and based on stable rules or thresholds.
Rely on human expertise when problems involve ethics, creativity, emotion, or ambiguity that cannot be formalized easily.
🤔 Eva’s questions¶
At this point, Eva is wondering about many questions.
How are we exactly “learning” whether a message is spam and ham?
What do you mean by “learn without being explicitly programmed”? The code has to be somewhere ...
Are we expected to get correct predictions for all possible messages? How does it predict the label for a message it has not seen before?
What if the model mis-labels an unseen example? For instance, what if the model incorrectly predicts a non-spam as a spam? What would be the consequences?
How do we measure the success or failure of spam identification?
If you want to use this model in the wild, how do you know how reliable it is?
Would it be useful to know how confident the model is about the predictions rather than just a yes or a no?
It’s great to think about these questions right now. But Eva has to be patient. By the end of this course you’ll know answers to many of these questions!

Supervised machine learning workflow¶
Supervised machine learning is quite flexible; it can be used on a variety of problems and different kinds of data. Here is a typical workflow of a supervised machine learning systems.
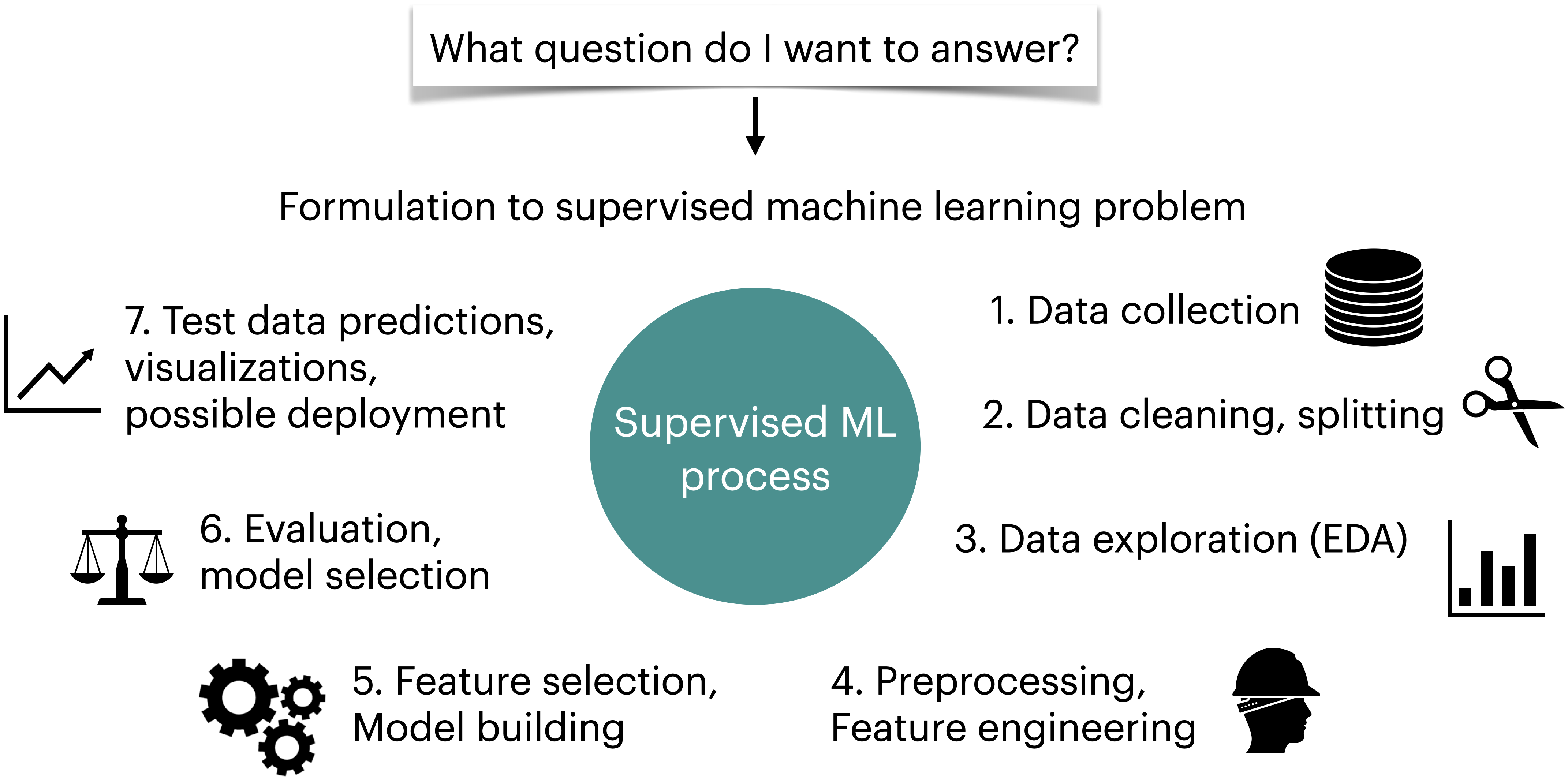
We will build machine learning pipelines in this course, focusing on some of the steps above.
❓❓ Questions for you¶
iClicker Exercise 1.1¶
Select all that apply: Which problems are suitable for ML?
(A) Checking if a UBC email address ends with student.ubc.ca before allowing login
(B) Deciding which students should be awarded a scholarship based on their personal essays
(C) Predicting which songs you’ll like based on your Spotify listening history
(D) Detecting plagiarism by checking if two essays are exactly identical
(E) Automatically tagging photos of your friends on Instagram
Summary¶
Machine learning is increasingly being applied across various fields.
In supervised learning, we are given a set of observations () and their corresponding targets () and we wish to find a model function that relates to .
Machine learning is a different paradigm for problem solving. Very often it reduces the time you spend programming and helps customizing and scaling your products.
Before applying machine learning to a problem, it’s always advisable to assess whether a given problem is suitable for a machine learning solution or not.
